find your purrsuit
find your purrsuit.
a playful, intentful perspective on your life.
science is great explanations.
reduce clutter.
reduce noise.
spread knowledge.
it's good, i promise!
art is experience, shared.
beauty gives joy.
don't make it too good, too wise,
if you do, you will not finish, not publish.
publish for more joy.
learn to respect your taste
then cherish it, take it seriously
then watch it evolve
don't take everything too seriously
it's no fun that way
what's more fun?
make fun of your ego.
toss it around.
your hubris, your pride.
let yourself have hubris, have pride.
then consider how silly it all is.
don't go all the way alone
movement alone is required
to some extent
but experience is richer together.
find someone to move with.
move in formation.
or move in chaotic joy.
enklere-2
Fra scratch
14.01.2026

Hva gjør du akkurat nå?
Jeg lærer meg HTML og CSS!
Finner du kvalitet i det?
Ja, det er storveis!
Hvorfor / hvorfor ikke?
Jeg har ofte ukes-mantraer, men i 2026 har jeg også et årsmantra. Nemlig, håndtverk. Fordi: er det noe jeg har en tendens til, så er det å hoppe på lette løsninger når jeg skal lage noe. Det smerter meg å se tilbake på mange av tingene jeg har laget og se at utålmodigheten ødela for meg. Jeg vet ikke akkurat hva denne utålmodigheten bunner i, men den er det motsatte av mestringsfølelse. Den er broren til imposter-syndrom. Dette er en loop jeg er stuck i, føles det som, og det har vært sånn i lang tid. Hvis jeg ikke skal skyndte meg, hvis jeg ikke skal bruke AI, hvordan skal jeg da få til å lage alt det jeg drømmer om? Tusen milliarder råd og gode idéer senere føler jeg meg like rådvill. Kanskje enda litt mer til og med.
Hva skjer så, når jeg prøver å gjøre ting ordentlig? Lære meg basic kode akkurat i det folk begynner å lure på om det i det hele tatt er noen vits i? Jeg lurer på hva det vil si å kjenne hver planke i huset man selv har bygget, å kunne ta en bilmotor fra hverandre og sette den sammen igjen, å bygge noe fra scratch, fra de minste bestanddelene. Å forstå hva innovatørene og kunstnerne før meg har måttet gå igjennom, hva teknologien jeg er med på å utvikle egentlig innebærer. Det ligger en slags takknemlighet, og en ydmykhet, i dette perspektivet. Mitt nye fokus fremstår som et lysglimt. En vei fremover, eller ut. Eller kanskje inn? Det er jo inn i klubben jeg vil. Til musikerne, til designerne, til kunstnerne, til koderne; til dem jeg ser opp til. Dette føles som noe annet enn nok en kul idé, ett nytt prosjekt, eller en gnist. Det kjennes riktig. Jeg skal ikke skryte på meg å ha mistet utålmodigheten, men jeg tror jeg er i ferd med å bli kjent med den på ordentlig.
Call to action—hva ønsker du kommentarer på fra de som leser?
Please ikke fortell meg at jeg jinxer det hele ved å skrive denne
teksten.

Julian
Fjernkohorter?
Samtaler med Julian, Line og Neno har fått meg til å fundere på terskelen for å publisere tekst på Mikrobloggeriet i dag.
Mikrobloggeriet har tre brukerflater: skriveflaten, leseflaten og kodeflaten. Disse disse tre har levd tett sammen så lenge Mikrobloggeriet har levd. Det har gitt oss kohesjon.
Kostnaden på å ha skriving, lesing og koding sammen er at man tvinges til å bry seg om alle tre. Å publisere en tekst blir det samme som å sjøsette ny kode. Skal vi fortsette å gjøre det sånn? Skal vi fortsette å kreve at de som bryr seg om skriving, også må bry seg om koding?
Hvis ikke blir spørsmålet hvordan vi skal håndtere fjernkohorter, kohorter som ikke lever i koden. Det minimale steget er å fortsette å ha fjernkohorter som markdown-filer i et Git-repo, men å tillate skriving i et annet Git-repo enn koden til Mikrobloggeriet. I så fall, hvordan “godkjenner vi” skriving fra en fjernkohort? Her trodde jeg først vi måtte ty til auth tokens eller annen personbasert identifikasjon. Men … det trengs egentlig ikke. Vi kunne sagt at vi stoler på enkelte repoer.
Da må man gjøre en Git push før ting blir publisert, men det er kanskje greit?
Det er også et spørsmål om hvorfor. Er “lettere” godt nok? Jeg liker ikke “det er lettere” som eneste begrunnelse. Hvis vi bare skal gå mot lettere og lettere, ender vi opp med å ikke produsere. Det er lettere å konsumere. Jeg tror heller vi snakker om fokus. Hvordan vi kan gjøre skriveflaten mer fokusert. Og ved å holde oss til Markdown-filer i Git, holder vi oss forholdsvis tett på de arbeidsflytene vi kjenner og støtter. Vi gjør ikke alt for mye i én jafs.
—Teodor
Mer kreativ med mer fokus?
Kreativitet handler om å koble ting man ikke hadde tenkt at hører sammen. Men kreativitet handler også om å lage seg et tydelig regelsett man holder seg innenfor, så man fritt kan utforske rommet man er i. Kunstnere kan lage seg intrikate regelsett de kan lage kunsten sin innenfor. Det kan gi sjarm og eleganse. Det blir ikke så kreativt hvis man skal male og vaske vinduer samtidig.
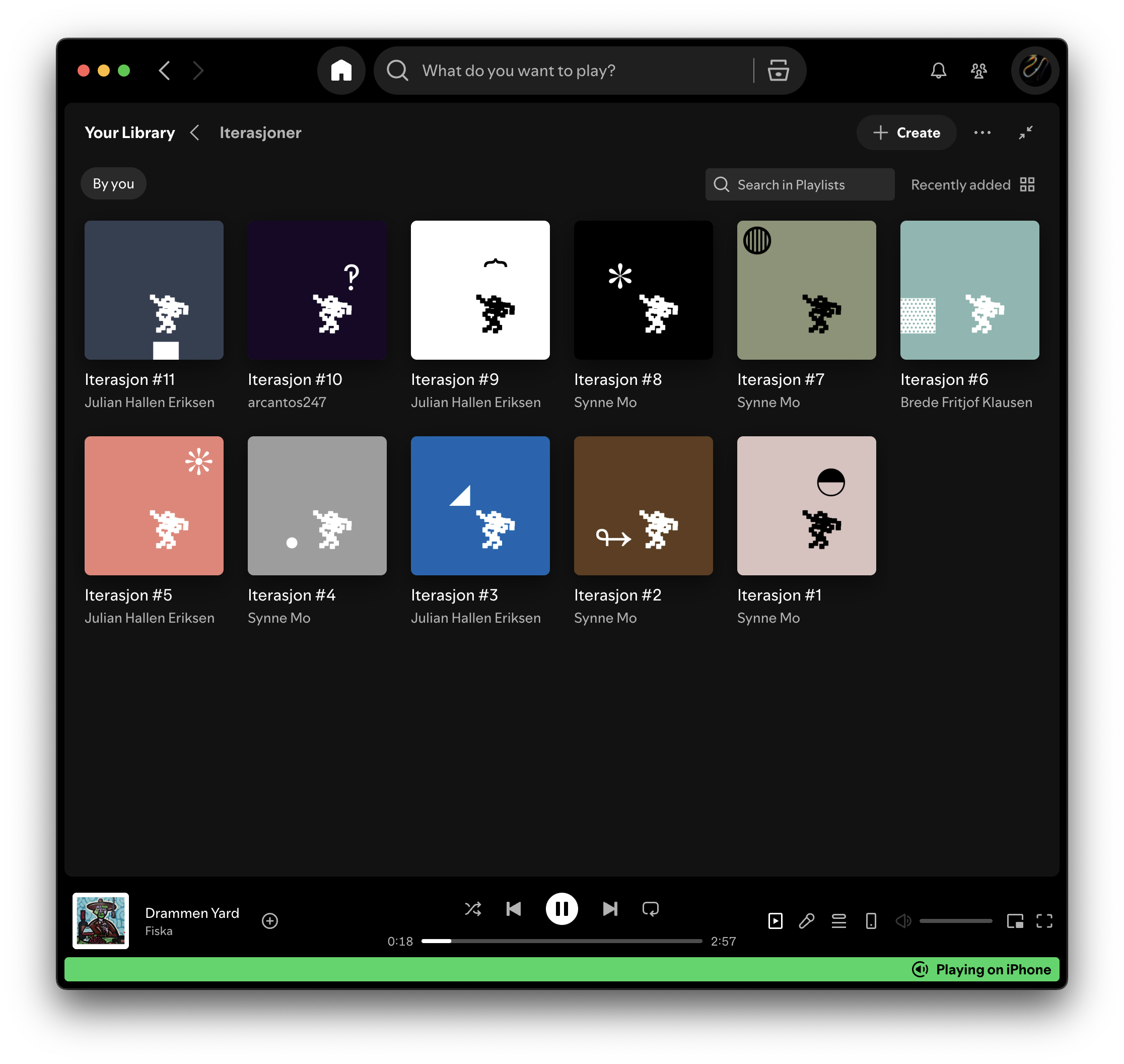
Iterasjoner
Vi har en interessant, liten lek gående på Iterate-kontoret. Hver uke lager vi en kontor-spilleliste i Spotify og fyller den med musikk sammen. Vi har klart å holdt dette ved like i 16 uker (iterasjoner), og det er ikke dårlig for en gjeng med altfor mange idéer!
Jeg tror det funker bl.a. på grunn av noen få, enkle regler. De er som følger:
- Alle kan legge til musikk
- Maks to sanger per person
- Maks ti sanger i en liste
Dette gjør listelagingen demokratisk og lavterskel.
I tillegg har vi et par små “estetiske” regler som gir konseptet en rød tråd. De er som følger:
- Alle listene skal ha tittelen Iterasjon etterfulgt av tallet som viser til listas plass i rekka
- Hver listes “cover art” bestemmes utifra fargen på albumcoveret til første låt i lista
- Hvert bilde har i tillegg den samme Iterate-logoen…
- … mens logoen leker med et nytt unicode-symbol for hver uke.
Min nye mobiltelefon
Mer og mer greier på én gang gjør oss mer og mer reaktive, og mindre og mindre kreative. Jeg trodde det ikke gjaldt meg. For to måneder siden oppdaget jeg at jeg hadde tatt feil. Og det satte spor!
På impuls kjøpte jeg meg ny mobiltelefon. Den har svart-hvit-skjerm som oppdaterer seg cirka én gang i sekundet. E Ink, sånn som Kindle. Den er helt nydelig å lese bøker på. Videoer kan du bare kan gi opp.
Den lille duppeditten har satt spor i hverdagen min. Jeg bruker telefonen mindre. Og når jeg bruker telefonen, er det for å gjøre en bestemt ting. Sende en melding. Lese en melding. Ringe noen. Så går den tilbake ned i lomma.
Plukker du opp telefonen når du kjeder deg? Det har jeg gjort. Den refleksen er nå sterkt dempet, men ikke borte. Jeg har prøvd å lese lengre tekster i stedet for å “sjekke internett”. I noen uker nå har jeg jobbet rolig gjennom en litt gøyal artikkel. I likhet med andre dyr, har vi mennesker evnen til å orientere oss og bevege oss i rommet vi er i. Men dyr kan ikke resonnere. Hvis jeg går hjemmefra 15:15, er jeg på Nydalen 15:33. Det klarer ikke dyr konkludere med! Men hvorfor? I Why do humans reason? Arguments for an argumentative theory, argumenterer Hugo Mercier og Dan Sperber for at vår evne til å resonnere har utviklet seg i et sosialt våpenkappløp. Jeg tjener på å argumentere for å få det som jeg vil. Og du tjener på å gjenkjenne bullshit i det jeg sier, så flokken vår ikke blir spist av sabeltanntigere der vi det var store dovendyr.
Alt skal ikke være nyttig. Noen ganger plukker jeg fram telefonen for å lese, og må legge den tilbake. Det var for tungt! Jeg trenger litt tid og ro når jeg skal lese tungt innhold. Men da er det at de få minuttene på T-banen får være diffuse? Ikke sprenge inn enda flere impulser når hodet er fullt.
Jeg føler ikke at jeg har funnet en ro, men jeg er i hvertfall på vei et roligere sted. Mindre mas, mindre skriking. Når jeg sitter på banen nå, føles det rart. 7 av 10 scroller i vei på mobilene sine! Og det er greit nok det, altså. Det er mange fine måter å bruke mobilen på! Men jeg lurer nå litt på om de etterpå vil være glade for mobilbruken.
En annen litt rar ting som har skjedd er at jeg tydeligere legger merke til farge og bevegelse. Apper har røde knapper som spretter og skriker “FARE FARE FARE”, men så er det bare at du ikke har lest reklamen. På skjermen min? Knappen er grå, og ting som egentlig skulle sprette rundt bare hakker. Når jeg leser en bok, vil jeg ikke at ordene skal hoppe fram og tilbake. Jeg vil ikke drive og scrolle. Jeg vil lese én side, så lese den neste. Mange av dagens brukergrensesnitt er fryktelig masete. For å vinne kampen om oppmerksomheten, gjør vi alt mer og mer høylytt! Men som kampen om å bli hørt på radioen på 90-tallet, er det vi, forbrukerne, som taper. Vi mister dynamikk, kontrast og tekstur. Når alt er høylytt, hører vi ikke lenger undertoner.
Sånn trenger det ikke være! Vi kan stoppe å bruke teknologi til manipulasjon. Når du stopper å konsumere, får du tid. Tid til å utforske, oppleve og forklare. Jeg ønsker at Mikrobloggeriet skal være en sunn ting å bruke tid pp. Både som skribent og som leser. Alle er velkomne! Hvis du vil skrive nå, kan du legge til en markdown-fil i LEIK. Push hvis du har tilgang, lag en PR ellers. Å skrive lar deg reflektere. Skriv om noe du har tenkt, noe du er interessert i. Eller dropp skjermen fullstendig og ta praten med venner og familie i stedet. Eller les om Olavs gamle mobiltelefon.
Fredelig jul!
Teodor
Kverulering: å bry seg om detaljer, eller å ikke skjønne kontekst?
I heimen blir jeg noen ganger omtalt som “Herr Heggelund”, eventuelt “Herr Teodor Kverulant Heggelund”. Da vet jeg at jeg har pirket for mye på hva begreper betyr! Utviklere kverulerer verre enn alle andre yrkesgrupper jeg har vært borti. Hvorfor?
- Hvis vi bruker bittelitt feil ord, tryner hele programmet.
- Begrepsapparatet vårt er hvordan vi organiserer koden vår. Når begrepsbruken spriker i koden, mister vi kontroll.
I Peter Naurs ord, Programmering er å bygge teori, og da må definisjonene dine være tydelige.
Men det finnes nyttig kverulering og unyttig kverulering. Nyttig kverulering er å bry seg om detaljene i kjernen av det man jobber på. Da må detaljene sitte! En grafisk designer må bry seg om enkeltpiksler og enkeltfarger, hvis ting er litt feil, synes det fryktelig godt. Tilsvarende for programmere, hvis en attributt er litt for bred, litt for smal eller bommer litt, lager du mental friksjon for alle utvikelere etter deg.
Unyttig kverulering er å gulpe opp “her er det noe feil!” av refleks, uten at det henger sammen med kjernen av det man jobber på. Jeg kaller dette drive-by-kverulering. Ikke gjør det uten å tenke deg om! Det kan hende det er nyttig å ta et steg tilbake og diskutere et begrep, men det kan også hende at du sporer av en ellers produktiv og hyggelig diskusjon.
Ny vår: utforskning, opplevelse og forklaringer
Etter en super arbeidskveld på Mikrobloggeriet i går med Olav, Line og Neno, har det blitt tydeligere for meg hva jeg ønsker å oppnå med Mikrobloggeriet.
Vi ønsker to ting: å gjøre det hyggelig å skrive på Mikrobloggeriet, og å gjøre det hyggelig å lese på Mikrobloggeriet.
Å ha det hyggelig kan knyttes direkte til dopaminreseptorer, eller noe dypere. Hvis det er dopaminreseptorene du er ute etter, sett en sprøyte i armen eller stirr på en skjerm for å konsumere.
Jeg fornekter denne formen for hygge. Den er slett ikke hyggelig. Den fører ikke til et hyggelig sted.
Så hva er et bedre alternativ?
Å utforske sammen.
… men hva vil det å utforske sammen bety? La oss pakke det ut.
- vi utforsker. Vi går nye steder vi ikke har vært.
- vi opplever. Mens vi utforsker, hva føler vi? Hvilken tekstur er vi i kontakt med?
- vi forklarer. Tingene vi har lært skal ikke dø med oss. De kan leve forbi våre snaue 100 år på jorda. Hvis ideene våre får slå rot, kan de leve forbi oss, og komme andre til gode.
Det er målet med Mikrobloggeriet. Hygge for skrive og for lesere, gjennom utforskning som resulterer i opplevelser og forklaringer.
Kom og skriv!
—Teodor
Det stille skriket
Rundt deg herjer stormen. Alt er viktigst! Pass på at du ikke går glipp av det! Sprakende farger, selgende ord, fristende fristelser og volumet på maks.
Konsumentenes umettelige behov for å bli stimulert. Et forfalsket stimulibehov skapt av industrien. Et stimuligbehov manipulert av teknologien. Teknologigigantenes slibrige måte å gjøre deg avhengig. Avhengigheten har ledet til en normalitet. Man er blitt vandt til støyen. Vandt til oppmerksomheten alle krever og vil ta.
Produsenten som nekter å brøle står igjen. I sitt stille skrik.
Neno & Teodor
Kode med SI-enheter: en smakebit
Jeg (Teodor) skal presentere på online-konferanse denne uka: fredag 17. oktober, 2025. Det er pengemessig gratis, og koster deg kun halvtimen jeg skal bruke til å snakke.
Dagens OLORM er en utfordring: Kan budskapet i presentasjonen min tilpasses til Javascript, og kjernen formidles for Javascript-kyndig leser på fem minutter? Jeg prøver.
Du har kanskje skrevet kode som denne:
const iterationTimeMs = 300;
const iterations = 53;
const totalTimeSeconds = iterationTimeMs * iterations / 1000;Det er vel ikke så ille?
Jo! Jeg ser en ting som “distraherer” koden. En kode-leopard, om du vil.
Fordi *-operatoren ikke kan forskjellen på millisekunder og sekunder, må vi regne ut enheten i hodet! Den mentalgymnastikken øker kognitiv last for oss utviklere. Mentalgynastikken øker også sannsynligheten for feil, vi må huske på å bruke de magiske tallene (her 1000) rett for å få rett enhet.
Den samme kodesnutten kunne sett sånn ut:
import * as munit from "munit";
import * as si from "munit/si";
const iterationTime = munit.mult(300, si.milli, si.second);
const iterations = 53;
const totalTime = munit.mult(iterationTime, iterations);Bedre?
Som alltid, å trekke inn biblioteker øker “tyngden” på programmet
ditt. Og én enklelt konvertering fra millisekunder til sekunder er
kanskje greit? Jeg skrev forresten en bug i koden øverst i første
versjon: iterationTimeMs * iterations * 1000;. Resultatet
ble én million ganger for stort!
Strukturert modellering av tall med enhet (SI eller andre ting, feks valuta) gir mer verdi jo vanskeligere problemet ditt her. Prøv deg på kilonewton per meter, sammen med lengder i millimeter, og momenter i kilonewtonmeter! Først med mentalgymnastikk, vanlige javascript-tall og enhetskonvertering i hodet. Så med operasjoner som forstår tall med SI-enhet.
Det var hele smakebiten. Kom på Macroexpand 2025 for å se resten!
Les mer eller meld deg på konferansen (penge-gratis, online) på scicloj.github.io/macroexpand-2025/
Eventuelt hjelp meg å nå på verdensveven ved å lage ståhei på Linkedin.
Ha en fortsatt god mandag!
Hilsen Teodor
Dyp intensjon og aktiv leveranse: to moduser for produktbygging
Etter en ellers helt super jobbkos-kveld med Julian, satt jeg igjen med en følelse av at det var noe som ikke helt stemte.
Mønsteret gikk som følger:
- Vi startet å gjøre noe
- Julian fikk en idé
- Vi snakket litt
- Jeg sa at vi måtte la ideen ligge for å bli ferdig med det vi startet på.
Det som skurret for meg var at jeg ikke hadde noen grunn til at vi måtte la det ligge. Etter en uke i underbevisstheten er svaret klarere for meg: vi var ikke tydelige på om vi var i dyp intensjonsmodus eller aktiv leveransemodus.
Når jeg jobber med egne fritidsprosjekter og får gjort noe, faller jeg inn på følgende prinsipper:
Jeg er uinteressert i å gjøre noe hvis det ikke er en motiverende grunn til å gjøre noe. Dårlig intensjon gir dårlig motivasjon, og da kan du la være, resultatet blir dårlig og arbeidet blir kjipt.
Hvis jeg skal få gjort noe, må veien ut i virkeligheten være kort. Jeg må få det ut. Det må bli ekte.
For å oppnå det, bytter jeg mellom to moduser: dyp intensjon og aktiv leveranse. I dyp intensjonsmodus følger jeg “hvorfor” spørsmålene helt ned, og gir meg ikke før jeg har drømt opp noe jeg ønsker at skal finnes i verden. I aktiv leveransemodus skal jeg få ned ekte arbeid, og levere én eller flere ganger i løpet av økta jeg setter meg ned. Jobber jeg med kode betyr det at jeg skal ha ekte kode som gjør noe interessant i løpet av samme dag.
Kvelden med Julian satte vi oss mål som var supre for å sikre aktiv leveranse:
- Julian skal ha sitt eget, personlige nettsted innen kvelden er omme
- Julian skal være i stand til å endre nettstedet sitt uten hjelp
- Nettstedet skal ta ett, konkret steg i retning av at Julian kan bruke nettstedet til å kommunisere noe han bryr seg om.
For å sikre at vi fikk til det, kuttet jeg oss av!
Men biten jeg ikke likte var at det var en greie jeg gjorde, ikke noe som vi gjorde sammen. For å sikre at vi gjør det sammen neste gang, noterer jeg meg følgende:
- Bruk dyp intensjon for å sikre at du lager noe du ønsker å lage
- Bruk aktiv leveranse for å sikre at du faktisk lager noe
- I samhandling, ikke bruk tvang for å bytte modus, velg byttene sammen.
Takk til Christian som har gitt meg praktisk trening for når man bør bytte til aktiv leveransemodus.
Teodor
Ta kreativiteten din seriøst!
Hva gjør du når inspirasjonen slår ned? Skriver du en idé bak øret, eller kapitaliserer du, og får noe ut i virkeligheten?
Hvis du blir vant til å ta ideene dine ut, kommer kreativiteten din til å endre seg: du kommer til å lære deg hvordan du endrer virkeligheten.
Noen ganger lurer jeg på hva som skjer hvis jeg ikke prøver å kapre en idé. Kan det være en bra ting? Tør stort sett ikke å prøve.
Kreativiteten i deg er to personer: skaperen og kritikeren. Du må trene begge! Skaperen kommer med forslag, kritikeren feier dem ned, én etter én. Men noen kommer gjennom. Og noen ganger må du lage noe som er dårlig nok til at du faktisk får det ut.
— Julian og Teodor
Mikro OG makro
Julian har satt fingeren så hardt på at man bør på med både mikro- og makroperspektivet at jeg ikke klarte la være å skrive litt. På Høstutstillingen i år finner dere en samling fugler:

Makro: 16 fugler!

… men … hva er dette? Et menneske, opp-ned?

I alle dager, enda et menneske på hodet til fuglen.

Og et menneske inni mennesket!
Jeg synes denne zoome-effekten er superspennende. Vi har detaljert, “ru” tekstur både på makro og på mikro. Som Julian så fint sa om Google Earth,
du kan zoome, og hvert nivå på skalaen er spennende.
Foto: undertegnede.
Teodor
Hypermedia forklart i to begreper
Hypermedia er en hjerne-basill som har grepet teknologer siden 1945 (Vannervar Bush), blitt beriket på 60-tallet (Ted Nelson), delvis kommet seg ut på Internett (Tim Berners Lee), men ikke helt (Roy Fielding, 2000-2009).
Den korte definisjonen av et hypermedia-system er:
- Serveren sender klienten tilgjengelige hypermedia-kontroller. En hypermedia-kontroll styrer hva du kan gjøre, som å navigere til en side eller flytte på en markør på et kart.
- Klienten beriker brukergrensesnittet med kunnskap om media-typer. Du kan starte med å støtte mediatypen tekst på klienten. Deretter kan du for eksempel berike klienten til å støtte markdown eller innsatt bilde.
Disse prinsippene er alt du trenger for å lage hypermedia-systemer!
Men hva har det å si i praksis? Når vi skriver webapplikasjoner der klienten vet mye om hva som foregår, får vi problemet med å synkronisere denne kunnskapen mellom serveren og klienten. Å bygge systemet på hypermedia løser dette:
- serveren vet alt
- klienten vet kun:
- hvor den er (feks med en URI),
- hva den kan gjøre (feks med lenker og skjemaer, kjent som hypermedia-kontroller),
- og hva ting er (mediatype).
Hvis dette vekker interessen din, anbefaler jeg på det varmeste Hypermedia: The First 2000 Years med Asbjørn Ulsberg, fra Javazone 2025.
Prat med Asbjørn etter fordraget gjorde at jeg til slutt skjønte hvorfor klienten måtte støtte mediatyper. Tusen takk, Asbjørn!
—Teodor, september 2025
Jeg gjentar, begrens uferdig arbeid!
Dette er uferdig arbeid:
Du kjenner uferdig arbeid selv. Du våkner opp til et kjøkken fullt av gårsdagens oppvask. Du har ikke plass til pc-en fordi pulten er full av bunker med papir.
Å rydde opp etter seg er mye lettere når du gjør jobben. Når du kommer tilbake, må du i tillegg gjøre MER ARBEID for å finne ut hva det var du egentlig hadde tenkt.
Begrens uferdig arbeid.
Stoler du på deg selv?
Interaksjoner med andre folk bygger tillit eller bryter tillit. En venn viser en ferdighet vi ikke ante om. En kollega følger opp med oss og har løst nøyaktig det problemet vi snakket om. En fremmed strekker ut en hånd uten at vi har gjort noe for å fortjene det.
Tillit bygges gjennom mange positive Interaksjoner over lang tid. Men tillit kan brytes med én handling. Denne teksten handler ikke om hvordan man bryter tillit.
Hvordan skal du bygge tillit til det selv? “fake it till you make it”? Det har jeg lite tro på, det føles hult og uærlig. Ta heller deg selv like seriøst som du tar folk du stoler på. Strekk deg etter en ny ferdighet. Hold noe du har lovet deg selv.
Ikke se på selvtillit som arroganse eller overmot. Se heller på deg selv som en person du ønsker å bygge en tillitarelasjon med.
Takk til Rune Larsen for spørsmålet “hva om du gjør det som bygger tillit?” ved kaffemaskina rundt årsskiftet 2019-2020.
Min gamle mobiltelefon
Mobiltelefonen min begynner å dra på åra. Jeg tror jeg kjøpte den tidlig 2019, så nå har den vel bikka 6 år gammel. Hurra! Joda, den henger litt bak en del yngre modeller. Batteriet er ikke helt konge og høytaleren er litt spengt, men den funker. Det jeg derimot merker aller best er at den ikke har de samme prosseseringsmusklene som nyere mobiltelefoner, eller datamaskina jeg jobber på fra dag til dag.
Og det gir meg innsikt.
Jeg får rasende fort tilbakemelding dersom en nettside krever mye ressurser. Eksempelvis er reddit.com ganske krise å surfe på min gamle mobiltelefon. Det samme opplever jeg til tider på nettsidene jeg selv er med å utvikler. De kjører rett og slett ikke slik jeg er vant med fra den raske jobbdatamaskina mi. Og motsatt finnes det andre sider hvor jeg merker veldig tydelig at det kjører raskt og bra.
Alt dette er det fint å være klar over. Jeg tror nemlig ikke jeg er den eneste brukeren med en gammel mobiltelefon.
Den omfangsorienterte designeren
Jeg digger å jobbe med designere som aktivt tar stilling til omfanget av jobben som skal gjøres. Les hvorfor.
Kontinuerlig leveranse
Designskissen skinner så du ser refleksjonen i den. Alt er perfekt. Fargene, forholdene. Teksten ser ut som en dessert fra en michelinstjernerestaurant. Du har et problem.
Hvor i all verden skal du starte?
Ifølge DORA (dora.dev/capabilities/continuous-delivery) leverer produktteam som praktiserer kontinuerlig leveranse jevnt over bedre produkter. Når man skal levere kontinuerlig må én bit leveres om gangen; og bitene som leveres informerer videre utvikling.
Men hvor i all verden skal du starte?
Den pixel-perfekte prototypen
Å finne det gode stedet å starte er en designjobb. Men det designet treffer ikke sluttbrukeren: det designet treffer utvikleren og designeren. En piksel-perfekt prototype peker ikke på hvor det er best å starte. Den gjør det motsatte: den sidestiller alle tingene som kan gjøres.
I stedet, finn ut hva første versjon av produktet skal gjøre. Hvem skal oppnå hva?
Hvis du ikke stiller det spørsmålet og svarer på det med en hypotese, har du ikke et tydelig mål. Da smetter “det skal se ut som på skissen” inn som mål i stedet. Da får du:
- Ukjent/uklar produktverdi
- Ukjent/uklar ferdigstillingsdefinisjon
- Masse work in progress.
Jeg mener vi bør unngå å ta opp work in progress når vi kan, se for eksempel OLORM-50: For mye opsjonalitet. Når målet med arbeidet i tillegg er udefinert, har vi lagd flere problemer for oss selv enn vi har løst.
Den omfangsorienterte designeren
Nivå 1 av jobben til den omfangsorienterte designeren er å ta “vi skal definere et smalt neste steg” seriøst. Ikke gjør mer enn nødvendig på én gang. Tenk “hvordan skal det tas i bruk” fra steg 1. Da lager vi så lite work in progress vi får til; vi setter oss i posisjon hvor vi kan fullføre.
Nivå 2 av jobben til den omfangsorienterte designeren er å kode det opp direkte i HTML og CSS. Lag noen HTML-filer og CSS-filer i kodebasen. Det blir da ettertrykkelig tydelig hvordan man kan blåse liv i prototypen med ekte data og ekte interaksjoner.
Med noen runder HTML og CSS i koden kommer utvikleren fort til å klø seg i hodet eller skjegget (eller andre steder med kroppshår) og tenke “hvorfor kan ikke designeren bare endre produktet direkte?” Det er et veldig godt spørsmål! Og svaret er ja. Det går. Men da må du rigge kodebasen så designeren faktisk får gjort jobben sin når desineren setter seg ned for å jobbe. Det betyr at designeren får fokusert på det visuelle utrykket, uten å bli distrahert av detaljer som ikke har med visuelt inntrykk å gjøre.
Visuelt arbeid på Mikrobloggeriet: ujålete CSS-filer, punktum.
Redesignet Mikrobloggeriet fikk vinteren 2025 er skrevet rett i CSS av Neno, som er utdannet designer. Neno kjører kodebasen lokalt, endrer CSS-filer og pusher og prodsetter med Git. Vi har gjort “push og prodsett” til én kommando. Hvis den var et bash-script, ville den sett cirka sånn ut:
set -e # ellers stopper ikke Bash når noe tryner, lol
./test.sh
./lint.sh
./try-deploy.sh # deploy feiler hvis appen ikke klarer å starte opp
git push“men er ikke gå rett i prod skummelt, da?” I praksis, nei. Det er tryggere. Det er lettere å forbedre systemet, inkludert å legge på nødvendig sikkerhetsnett.
Den omfangsorienterte designeren lar produktteamet levere raskere og bedre
Design-utvikler-interaksjonen i Mikrobloggeriet-arbeid er såpass bra at jeg vil jobbe hardt for å beholde den flyten. Som utvikler får jeg fokusert på domeneproblemer og tilgjengeliggjøring av data, og slipper “implementer denne plx”-gjørejobber. Det gjør at vi klarer å shippe redesign på rekordtid på et hobbyprosjekt vi gjør ved siden av vanlig jobb.
Hvis du er designer eller utvikler, anbefaler jeg å prøve det. Gøy og bra :)
Takk til Neno Mindjek og Eirik Backer for gode diskusjoner om samspillet mellom utviklere og designere, og til Christian Johansen og Magnar Sveen for gode tanker om hvordan framside-kode kan struktureres på enkelt vis.
Leik gir liv gir samhold gir kvalitet
Lag noe sammen! Finn glede i å skape! Med en gruppe får du liv og samhold. Det vi lager sammen er vårt, og blir større enn individene.
At du ikke trenger å bestemme alt selv er bra av to grunner:
Du kommer lengre med flere. Når du tar alle valg, kommer du til å gå tom for damp. Med flere kan man ta tak i problemene sammen, og dra litt hver av oss.
Det du lager blir bedre. I “hva er bra?”-spørsmålet kan du få med flere stemmer. Folk har forskjellige referanser, og de referansene får du bruk for.
For å komme i gang, lek. Ikke sett kjipe forutsetninger. Ikke lag deg en tvangstrøye du ikke vil gå med.
Så, lek!
… men … hva så? Lek er overraskende nok ikke alltid gøy. Jeg kan i alle fall gå lei. “Nå har jeg tulla nok, nå vil jeg gjøre noe ekte.”.
Da går du videre. Lek blir til liv. Livet skaper over tid samhold. Og det samholdet bygger kvaliteten.
Liv på Mikrobloggeriet
I det siste har Mikrobloggeriet vært livlig! Jeg hadde en dritkul opplevelse på mandag denne uka. Neno nevnte fredagen før,
du teodor
jeg må si noe
det gjelder barnet ditthææææææh. jeg har jo ikke noe barn?
Nei, Neno, det er ditt barn!Lol, ta den. Jeg kan også tulle.
neeei, ikke det barnet
mikrobloggeriet
vi skal GJØRE TING med mikrobloggerietåååååå
så nå er vi her :)
ting er ikke helt som før. På en god måte, vil jeg si.
Mer liv på Mikrobloggeriet
I dag må man lage nye dokumenter med
./mblog.sh COHORT.
Du kan spørre deg selv “… men er det lett for alle, da?”, og svaret er nei!
Så vi prøver oss med en ny kohort.
Den heter LEIK.
Den er hakket mer leken enn de eksisterende kohortene.
Dokumenter på leik har et tall, og skrives i Markdown. De ser da feks sånn ut:
1.md(det er sånn denne ser ut).
Og den ligger i
text/leikpå Mikrobloggeriet.
Det er ikke noen flere steg :) Burde være lett å skrive fra web-editoren uten å kjøre noe kode. Og vanskelig å gjøre feil.
Men med litt leik får vi kanskje mer liv, samhold og kvalitet!
MIKROBLOGGERIET_2.0_WIP
Mai 2025
2025-05-05
Opsjoner:
Gammalt
Mars 2025 / Ny forside
16.3.2025: indigo, høyre, venstre
17.3.2025: css, markdown->hiccup, lazy-load, pandoc, ny front og farger
18.3.2025: css + visited state
19.3.2024: lagt til POC-kohort som er lettere å skrive rett fra github, LEIK Ønske til designerene våre: vurdere (et lite hakk) tydeligere overskrifter? Litt vanskelig å skille seksjonene i feks https://mikrobloggeriet.no/#leik-1 fra hverandre.
Work in progress:
OJ-6: Noen tanker boken Ekko - Et essay om algoritmer og begjær
I februar leste jeg boken Ekko - Et essay om algoritmer og begjær av Lena Lindgren. Boka kom ut i 2021, og er nok kjent for flere av dere da den mottok stor ros fra litteraturkritikere, og vant priser som Brageprisen for beste sakprosabok. Jeg hadde fått med meg at boka fantes, men det var ikke før i år at den havnet forran meg.
Boka, eller essayet, ble skrevet som et forsøk på å forstå samtiden, og hvordan Silicon Valley, medieteknologien og utviklingen av sosiale nettverk har bidratt til å påvirke den. Lindgren prøver å tolke fremveksten ekkokammer, hatprat, splitting og radikalisering, avhengighet, synlighet og oppmerksomhet, og effektene som har bidratt til disse fenomenene. Sentralt for fenomenene er oppmerksomhetsøkonomien, og algoritmene som er utformet for å maksimere inntjeningen. Og algoritmene har forstått at disse fenomenene er lønnsomme.
Essayet bruker den romerske myten om Ekko og Narcissus som en rød tråd, eller anologi for å beskrive disse fenomenene. Myten handler om Narcissus, som er forelsket i seg selv og sitt eget speilbilde, og nymfen Ekko, som forelsker seg i Narcissus. Ekko er blitt forbannet etter å ha bablet meningsløshet for å distrahere, og har nå kun mulighet til å gjenta det siste andre har sagt. Myten ender med at Narcissus dør, besatt av sitt eget speilbilde, mens Ekko blir revet i stykker, besatt av Narcissus, og lever videre kun som en stemme som gjentar andre. Det er ikke åpenbart å trekke parallene mellom denne cirka 2000 år gamle fortellingen, og hvordan vi som menneskers oppførsel er i den nye medieteknologien og sosiale nettverk. Jeg synes essayet fletter disse to sammen på en spenennde måte.
Men det var kanskje nok om selve boken. Den er ikke så lett å beskrive i korte trekk. Jeg tenker derfor å skrive kort om hvorfor jeg likte denne boka, og hva jeg fikk ut av den.
Jeg likte denne boken, først og fremst fordi den gav meg noe mer klarhet i en stadig mer forrvirende verden. De siste 10 årene, og kanskje særlig fra valget det amerikanske valget i 2016, hvor Trump for første gang ble stemt inn som president, har endringene skjedd fort. Folks oppførsel og handlinger oppleves mer og mer irrasjonelle, og det er vanskeligere og vanskeligere å forstå hvorfor folk gjør hva de gjør. Jeg opplever at vi lever i stadig mer forskjellige virkligheter. For min del har denne følelsen kun økt siden 2016. Og særlig denne siste måneden hvor Trump igjen har kommet til makten i USA, og verden har blitt veltet på hodet i forrykende tid.
Nettopp denne utviklingen synes jeg Ekko diskuterer på en god måte. Særlig synes jeg Lindgren gjør en god jobb i å belyse mekanismene som gjør at vi mennesker oppfører slik vi gjør, og hvordan algoritmene bidrar til dette. Det hjalp meg med å forstå hvorfor Trump gjør som han gjør nå, hvorfor teknologi-lederene i Silicon Valley stiller seg bak, og hvorfor mennesker gjør statig mer rare og uforståelige ting.
Jeg kommer ikke til å diskutere alt dette i denne mikrobloggen, da det fortsatt er vanskelig å sette alle tankene i ord, og. Jeg oppfordrer derimot til å lese Ekko - Et essay om algoritemer og begjær. Den er kort og bra skrevet, og veldig dagsaktuell. Også ønsker jeg gjerne å diskutere disse temaene videre.
Olav 📣

Unngå forgrening!
Jeg har blitt mye mer var på når jeg innfører forgrening i kode enn før. Men hva i all verden skal det egentlig bety?
Å “innføre en gren” betyr noe mer enn å kjøre
git switch --create, ikke sant?
De første grenene springer ut fra trestammen
Ordet “branch” på norsk betyr “gren”. Trær har grener.

Et tre har én trestamme. Når trestammen først forgrener seg, får vi grener ut fra trestammen.
Trestammen forgrener seg og blir til flere grener. Grener kan også forgrene seg i flere grener.
Hver if lager en
ny gren i koden
Før hadde denne koden én logisk flyt. Nå har den to!
Hver gang koden skal feilsøkes, må vi skjønne begge grenene i koden. Kunne vi latt være å forgrene? Når vi forgrener fra nye grener gjør vi det enda vanskeligere for oss selv.
Jeg liker å forgrene i starten, og deretter la koden flyte så rett som mulig.
Hver
git switch --create lager en ny gren i hodet til
utviklerne
Vi stopper ikke alltid ved skillet mellom lokal kode og produksjon. Git kan holde styr på historikken til koden. Git kan også la oss lage så mange grener vi ønsker. Det er ingen grenser! Jo flere grener vi lager, jo flere grener må vi kjenne forskjellene mellom. Og når vi skal slå sammen to grener (anti-forgrene?), får vi alle forskjellene tilbake i fleisen.
Hvis vi lar være å forgrene, slipper vi å holde styr på alle grenene.
Unminifying av kode med LLM
Akkurat nå jobber jeg med å skrive om noe funksjonalitet i en gammel app. Spesifikt skal jeg bytte ut kartleverandør. I bunn er det Leaflet som brukes til å vise kartene, men Leaflet lå bak en wrapper fra den forrige kartleverandøren. Derfor var det ikke bare å erstatte det gamle kart-endepunktet med det nye. Jeg var derimot avhengig av å vite hva som skjedde bak kulissene, men wrapper-koden var minified. Da er ikke koden særlig lesbar.
For en stund tilbake kom jeg over denne artikkelen på HN, som i bunn og grunn er en bedre versjon av dette blogginnlegget jeg nå sitter og skriver. Poenget er at LLMer er overraskende gode på å unminifye kode, og det kan man bruke dersom man plutselig har behov for å forstå noe minified kode.
Jeg limte koden min inn i Claude, og ut fikk jeg en penere formatert kode, litt mer deskriptive variablenavn, og noen kommentarer. Kommentarene var ikke alltid riktig, men nå manglet jo modellen litt kontekst også. Uansett fikk jeg lesbar kode ut, som jeg kunne bruke til å forstå hva jeg trengte å ta med videre når jeg skulle skrive meg ut av denne wrapperen.
Tidlig verdi, høy kohesjon og lav kobling: tre lekser fra Mikrobloggeriet
Morn :) Teodor her. Å jobbe med Mikrobloggeriet har vært en læringsreise for meg. Fra starten ønsket jeg å lage en arena der vi kan lære sammen og være nysgjerrige; der selve systemet også er formbart og inkluderende. Per 2024-12-21 teller Mikrobloggeriet 1669 commits, og om lag 100 publiserte mikroblogginnlegg (som får meg til å tenke at en statistikkside hadde vært gøy).
Snøen faller i Oslo, og kanskje roen vil senke seg etter hvert. Å roe ned for meg handler ofte om refleksjon og langsiktighet. Når stresset letter litt og antallet ting som skal gjøres hver dag faller, kommer motivasjonen til å se litt tilbake og å se litt fram snikende.
Jeg vil gå gjennom tre ting jeg mener har vært viktig, hvorfor det har vært viktig, og hvorfor det som var viktig ikke var intuitivt i første omgang.
Tidlig verdi
Målet mitt med Mikrobloggeriet var ikke å ha en kodebase jeg kunne pelle på, det var å skrive sammen om ting vi hadde lært. Jeg definerte verdi som “vi som skriver på Mikrobloggeriet skal få noe ut av å skrive sammen”.
Første milepæl var å få en start på innholdet. Her er committen der Lars Barlindhaug skrev OLORM-1:
https://github.com/iterate/mikrobloggeriet/commit/b42b365f00e1ad7630f21cd43186804aee8e392a
Og her er hele innholdet:
# En god natts søvn
I går holdt jeg på en litt kompleks refaktorering hvor jeg skal hente
fargevarianter for en garnpakke fra to forskjellige steder i databasen, avhengig
av om de er opprettet av designeren av oppskriften eller strikkeren har laget
sin egen fargevariant. Det endte med at jeg ikke ble ferdig før jeg måtte gå
hjem, og jeg så for meg at jeg trengte å bruke et par timer på det i dag. Hadde
jeg blitt på jobb hadde jeg nok også lett brukt et par timer.
Når jeg kom på jobb i dag så jeg umiddelbart hva som var feil, et lite stykke
unna der jeg jobbet i går, og fikset alt på ca 5 minutter.På det tispunktet fantes ikke nettsiden. Poenget var ikke å lage nettside, poenget var å skrive sammen og dele hva v i har skrevet.
Lekser:
Tidlig produktverdi er ofte fullstendig frakoblet hva man har skrevet av kode. Målet med Mikrobloggeriet var å skrive sammen for å dele, lære og utforske, ikke lage webapp. Teknologien for å publisere tekst på nett er velprøvd, vi har hatt HTML i 30 år. Usikkerheten rundt om folk kom til å prøve å skrive én gang, og deretter om folk kom til å fortsette å skrive var betydelig større.
Hva som gir mening fra et produktperspektiv og hva som gir mening fra et utviklerperspektiv er her helt forskjellige ting, og begge deler må funke. Hvis du skal ta på deg både produkt og utviklerhatten, må du både definere et verdiforslag du kan ta ut i verden (“product discovery”) og faktisk ta verdiforslaget ut i verden (“product delivery”).
Ting som lever i verden og brukes av ekte folk er gjerne enda mer spennende å putle med enn stæsj man koder litt på på egen maskin! Når ekte folk bruker verktøyet du har laget, blir alt mer ekte.
Høy kohesjon
Holdningen min til arkitektur i Mikrobloggeriet var lenge at ett navnerom holder. Jeg vil dra fram ett blindspor, og en suksess. Vi starter med blindsporet.
Helt i starten splittet jeg opp Mikrobloggeriet-koden i to mapper: CLI-et for å skrive innlegg, og HTTP-serveren som skal vise Mikrobloggieriet på Internett. Det lagde flere problemer enn fordeler.
- Editorer som Emacs og VSCode gir mer hjelp når man redigerer én mappe med kode
- Når man har én mappe med kode har man ett sett med avhengigheter
- Når man har én mappe med kode, er å installere avhengighetene til den ene kodebasen noe man gjør én gang
- Når man har én mappe med kode, er bruken av koden frakoblet fra koden. Man står fritt til å organisere koden der man vil logisk i strukturen, uten å tenke på hvilket underprosjekt som har hvilken funksjonalitet.
Mikrobloggeriet er nå én mappe med én kodebase, og det har fungert mye bedre for meg. Kutt kompleksitet, og bli glad! 😊
I selve server-koden gjorde jeg et valg jeg i dag er mer fornøyd med:
putt server-ting i mikrobloggeriet.serve inntill ting har
et bedre sted å være. Serveren startet som en router og noen
HTTP-handlere. Routeren sier hvor en gitt HTTP-request skal, og
HTTP-handlere tar inn en HTTP-request og gir en HTTP-respons. Jeg tror
både Johan og Olav har bemerket at mikrobloggeriet.serve er
stor! Og det er jeg helt enig i. Store moduler som ikke er “ferdig
splittet” er litt vanskelige å sette seg inn i. Det går liksom ikke å
“skjønne hele greia” på ett forsøk, man må heller se på hvordan koden
brukes i enkelte konkrete tilfeller. Starte med å skjønne hva som skjer
på en GET /, gå videre derfra.
Lekser:
Ved å splitte opp for tidlig risikerer du å splitte opp på feil måte, som kan gjøre enda mer vondt enn å ha ting samlet en stund. Ekstremvarianten er tidlig, voldsom splitting i separate tjenester, som Olav advarer mot i OJ-4:
Dette gjør også appen, og eventuelt podden veldig mye mer sårbar til å krasje. Ta hensyn for dette, evnt ved å splitte ut egen logikk for orkestrering, og tenke på retry-mekanismer. Mikroservice-helvette lusker visst overalt. Mitt beste tips her er å sørge for god tilgang til informasjon om ressursbruk i kjøremiljøet.
Store moduler kan gjøre vondt når man ikke kjenner koden.
Lav kobling
Så, hva gjør man når modulen har blitt for stor? At modulen er for stor betyr gjerne at den gjør for mange ting. Hvis vi klarer å trekke noe til side, er det bra!
MEN.
Hvis det faktisk skal bli enklere, må det vi trekker til side være lavt koblet med resten av koden. Ellers blir det ikke enklere å jobbe med!
Her kan du vurdere om det funker ved å lese koden direkte.
- Leser koden i hovedmodulen bedre etter at du trakk til side et lite problem?
- Hvor mange ganger kaller du fra hovedmodulen til sidemodulen?
Hvis hovedmodulen faktisk leser bedre etter at du har splittet opp, og det ikke er alt for mange funksjonskall fra hovedmodulen til sidemodulen, har du lav kobling!
God jul :)
Håper julefreden senker seg hos deg også!
Hilsen Teodor
☃❄🎄
Les, skriv, og lær! Det er lov å være nysgjerrig!
Ikke sant, jeg må huske å stille spørsmål til publikum!
Jeg oppfordrer til det sterkeste til å skrive på Mikrobloggeriet, både om ting du lærer (innlegg) og kode. For meg har det vært superviktig, gitt meg et lass av nyttige erfaringer, samt mye mer mot bak meningene mine om produkt og teknologi.
Hvis du synes dette innlegget var spennende, oppfordrer jeg til å skrive et eget innlegg! ITERATE-kohorten er for eksempel et fint sted å skrive hvis du jobber i Iterate.
OJ-4: Hodeløse nettlesere i produksjon
Det finnes noen grunner til at du ønsker å kjøre en headless nettleser i produksjon. Det kan eksempelvis være å ta skjermbilder av en nettside, generere PDFer, skraping, automasjon, eller ende-til-ende tester. Altså om det er noe du må inn i nettleseren for å verifisere eller fikse. Bibliotek som Playwright, Puppeteer, Selenium og Cypress gjør det høvlig enkelt å skrive kode som interagerer med nettleseren. Og rett slik kan du automatisere hva nå enn du ønsker å gjøre i nettleseren. De vanligste headless nettleserene er Chromiums, Firefox, og Webkit, altså som de vanligste ikke-headless nettleserene, bare headless.
For ordens skyld: en headless nettleser er da en nettleser uten et grafisk brukergrensesnitt, og da ganske egnet for å kjøre i bakgrunnen på din maskin, eller, som jeg skal komme tilbake til, på en server.
Vi jobber med kode som blir vevd inn blant annen kode fra flere andre team, til et og samme produkt. Derfor opplever vi støtt og stadig at endringer utenfor vår kode brekker funksjonalitet vi har ansvar for. Og akkurat derfor fikk vi idéen om å lagen tester som alltid gikk automatisk i bakgrunnen, og sjekket disse tingene for oss. Dette har også medført en del fallgruver, så jeg tenker å vie resten av dette skriveriet til.
1. Ikke kjør en nettleser i produksjon om du absolutt ikke må
Stort sett ønsker man å kjøre slike programmer lokalt eller kanskje tester i CI. Et vanlig bruksområde er ende-til-ende tester som trykker seg rundt i applikasjonen din, sjekker at ting er der de skal være, men også at resten av systemet som skal tjene front-enden fungerer. I de aller fleste tilfeller er dette mest relevant å teste ved endringer. Har du ikke behov utover dette, eller som du tenker det går fint å kjøre fra din maskin er min anbefaling at du holder kjøringene der.
Men så finnes det jo alltid en eller annen grunn til at du kanskje føler du må dette alikevel. Eller en slik grunn greide i alle fall vi å pøske frem for oss selv. Det har jo også gitt litt hodebry.
2. Nettlesere krever mye minne og CPU
Appen din bruker nødvendigvis ikke så mye ressurser, men det gjør en
nettleser. Det er jo tross alt et ganske stort program man trekker inn.
Derfor må man sørge for at man har gitt tilstrekkelig med ressurser. Og
det nettleseren får, er den ofte gira på å ta. For oss har dette
innebært mye OOMKilled og en del store CPU-spikes, eller
throttling om man har limits på slikt. Det krever rett og slett en del
skruing på knapper og måling av bruk for å lande på en ideel
ressursallokering og skalering. I min erfaring går det ofte fint med
litt CPU throttling for noen tester, men blir det for mye endte
vi i prakis opp med flaky tester fordi ting lastet for treigt.
Dette gjør også appen, og eventuelt podden veldig mye mer sårbar til å krasje. Ta hensyn for dette, evnt ved å splitte ut egen logikk for orkestrering, og tenke på retry-mekanismer. Mikroservice-helvette lusker visst overalt. Mitt beste tips her er å sørge for god tilgang til informasjon om ressursbruk i kjøremiljøet. For Kubernetes har jeg hatt veldig god nytte av k9s CLI og Grafana.
Og til slutt så er det jo noen som skal betale for skymorroa, og selv om man ikke alltid blir eksponert for sluttsummen selv.
3. Bruk grensesnittet ditt bibliotek gir til nettleseren riktig
Jeg tenker jo at dette skulle være åpenbart, helt til jeg skøyt meg
selv i foten ved å glemme browser.close(). Dette er altså
Playwright-funksjonen for å lukke en nettleser, og ved å ikke lukke den
mellom hver test endte jeg opp med svært mange nettlesere, og til slutt
svært mange OOMKilled og drepte podder. Skriv denne koden med omhu.
Her er det også veldig mange måter å optimalisere, som ikke nødvendigvis er helt intuitiv. Eksemplevis kan dette være parallelisering, eller lage en kø for å kjøre ting sekvensielt. Dette er avhengig av hva du skal, hvilket bibliotek du bruker, og hvor mye ressurser du har tilgjengelig. Her er det relevant dokumentasjon for ditt bibliotek som gjelder, men for resten har jeg ikke funnet noen tydlig informasjon om hva som er best. Vi kjører ting sekvensielt med en kø.
Her er det også verdt å nevne at nettlesere kan ta inn massevis av argumenter på oppstart, hvor det finnes noen som er ekstra relevant for å kjøre en headless nettleser i containerised miljøer (eksempelvis Docker). Disse varierer fra nettleser til nettleser, og slik jeg tolker det er det viktigere for headless Chromium og headless Firefox, og mindre viktig for headless Webkit. Mange av disse argumentene kommer med avveininger. Eksempelvis ved å skru av sikkerhetsmekanismer som sandboxing for bedre ytelse, eller redusere ytelsen på kost av poteniselt mer flaky tester.
Her er en god oversikt over argumenter til Chromium.
Jeg har ikke funnet en tilsvarende god oversikt for Firefox config dessverre.
4. Nettlesere lager prosesser som ikke nødvendigvis blir ryddet opp skikkelig
Jeg har også fått inntrykk av at nettlesere har en tendens til å starte egne prosesser som ikke nødvendigvis blir avsluttet når man avslutter nettleseren. Dette kalles noe så kult som zombie processes! Skrekk og gru!
Særlig i containeriserte miljøer er det viktig å huske å drepe disse
før de spiser opp PIDer (prossess-IDer for aktive prosesser) og minne.
For å drepe zombier anbefales det å bruke et init-system i
containeren, som dumb-init eller tini. Disse konfigureres da
som en parent-prosess til det du tenker å kjøre i containeren, også har
innebygd logikk for å rydde opp i nettopp zombie prosesser. I nyere
versjoner er forresten tini bygd inn Docker og Podman, men må
da startes på run med flagget --init. Hvordan
jeg konfigererer opp args for docker run i kubernetes har
jeg ikke blitt helt klok på, så jeg ruller med tini for nå.
Selv med dette virker det ikke alltid som nettleser-prosessser blir ryddet opp helt skikkelig, i alle fall mens nettleserne driver å kjører. Jeg har brukt programmer som htop til å aktivt monitorere prosessene som lever i min container for å prøve å få bedre bukt på dette. Om noen har noen tips akkurat her tar jeg gledelig i mot.
Avslutningsvis vil jeg gjerne gjenta at poeng 1. Prøv å unngå å prodsette disse beistene om du kan unngå det. Hodebryet er så mangt, og jeg er ikke i mål. Det finnes også selskaper som tilbyr headless nettlesere som en tjeneste. Det virker veldig digg, men jeg har ikke testet de. Jeg har derimot hentet en del tips og inspirasjon fra ett av de her.
Har du noen tips eller innspill?
-Olav
Lynraske modultester med én tastekombinasjon
Å oppleve lynraske modultester i bruk har endret på hvordan jeg liker å strukturere og jobbe med kode. Kanskje lynraske modultester er noe for deg også?
Hvordan skriver du koden din?
Lynraske modultester med én tastekombinasion er en fryd å jobbe med fordi det gir en super boost til feedbacken du får når du skriver kode. Kanskje noe å vurdere hvis du ikke har prøvd? Les videre for å høre hvorfor du bør ta lynraske modultester seriøst, og hvordan du får det til med Clojure, Javascript, Go og Python.
Hvorfor du bør ta lynraske modultester seriøst
Du kan kode raskere hvis du kan sjekke om koden funker raskere. Hvis du vet nøyaktig hva koden gjør, er du klar til å endre den.
Med lynraske modultester får du bekreftet at koden gjør hva du tror den gjør umiddelbart. Det lar deg endre og legge til funksjonalitet uten frykt. Når du også stoler på at testene er korrekte og dekker det du bryr deg om, kan du også sjøsette ny kode straks den er skrevet og testene er grønne.
Så, hva er god nok feedback fra koden din? Jeg vil beskrive feedback langs tre akser.
Forsinkelse. Hvor lenge må du vente? Ti millisekunder? Ti sekunder? Hvis du kan holde feedback-loopen din lynrask er det helt supert! Her bryr jeg meg om “opplevd lynraskt”. En 60 Hz-skjerm gir deg et nytt bilde hvert 16. millisekund. 16 millisekunder er lynraskt! 200 millisekunder er OK. 1 sekund er dårlig.
Bredde Hvor mye dekker feedbacken du får? Når testene er grønne, stoler du nok på testene til å gå rett i produksjon med koden? Når du lener deg på modultester i arbeidet du gjør, må du kunne stole på at modultestene dekker det du bryr deg om i modulen.
Ergonomi. Å scrolle gjennom tusenvis av linjer printet i et svart vindu med hvit tekst er dårlig for hodet ditt. Se for deg at du kjører en bil, men i stedet for å se veien foran deg, får du en tekstkonsoll med linjer skrevet ut av en kjøreassistent. Det er null sjanse for at jeg setter meg i passasjersetet i den bilen.
Lynraske modultester er bedre målt langs feedback-forsinkelse, feedback-bredde og feedback-ergonomi enn andre mekanismer for feedback fra kode jeg har prøvd før1.
Modultester med én tastaturkombo i Clojure
I Clojure kaller vi modulene våre for navnerom. Hvert navnerom bor i hver sin fil. Vi legger oppførselen til modulen i én fil, og modultestene i et annen fil.
Lag deg en tastaturkombo som gjør følgende:
- Lagre filen du har åpen.
- Re-evaluer filen du har åpen.
- Kjør modultestene, og gi deg selv et sammendrag. (Dette må fungere både når du har markøren din i filen med oppførselen til koden, og når du har markøren din i filen med testene)
Ferdig! Nå har du det!
Hvis du vil prøve Emacs-oppsettet vårt, har magnars/emacsd-reboot
denne tastaturkomboen bygget inn som C-c C-k. Andre
Emacs-oppsett kan prøve M-x cider-test-run-ns-tests, og for
Calva med VSCode kan man sjekke dokumentasjonen for Calva Test Runner. Calva /
VSCode har også en helt nydelig støtte for å kjøre flere
tastatursnarveier etter hverandre med den fine kommandoen
runCommands. Les mer fra Peter Strömberg (skaperen av
Calva) i VS
Code runCommands for multi-commands keyboard shortcuts.
Jeg anerkjenner at å skrive lynraske modultester kan være en utfordring. Det kan til og med hende at du må tenke på hvordan du kan få testene til å bli raske når du deler systemet ditt inn i moduler.
Modultester med én tastaturkombo i Go og Javascript
Go og Javascript er godt egnet for en kjapp test-loop fordi det er raskt å kjøre en fil. At det er kjapt å kjøre en ny fil kan være et godt alternativ til et kjøretidsmiljø der du kan laste ny kode.
Lag deg en tastaturkombo som gjør følgende:
- Lagre filen du har åpen.
- Kjør modultestene til filen du har åpen, og gi deg selv et sammendrag.
Når vi ikke bruker et dynamisk kjøretidsmiljø, slipper vi å tenke på hvilken nye kode som skal lastes inn.
Modultester med én tastaturkombo i Python
Python har fått sitt eget avsnitt, fordi etter min erfaring, kan Python-tolkeren ta litt tid når du importerer tunge biblioteker.
Python har imidlertid et dynamisk kjøretidsimiljø! Kanskje du er uenig, eller aldri har hørt om det før? I så fall, sjekk importlib!
>>> import importlib
>>> help(importlib)Se! Standardbiblioteket kommer med en modul laget for å laste ny
kode! Hvis du fremdeles er på Python 2, kan du se etter reload
(som ikke krever import av noen moduler).
Så lager du deg en tastaturkombinasjon som gjør følgende:
- Lagrer filen du har åpen.
- Laster ny kode fra filen med
importlib. - Kjører testene for den nylig importerte modulen.
Gjør det!
Koding skal være gøy! Hvis du rigger deg til med solid oppsett for testing, kan du fokusere på hva du vil at koden din skal gjøre, i stedet for å bruke dagen på å pønske på hvorfor koden tryner.
Appendix A: moro med dynamisk lasting av ny kode i Python
I 2017 og 2018 jobbet jeg med styrkeanalyse av en bru som kanskje i framtiden kommer til å krysse Bjørnafjorden. Bjørnafjorden ligger omtrendt midt mellom Bergen og Haugesund. Verktøyet jeg brukte til modellering er Abaqus. Første versjon av Abaqus kom i 1978: da kunne man skrive 3D-modellen sin som tekst i en inputfil, og få resultater. Alt implementert i Fortran!
Dagens Abaqus har både GUI og innebygget Python-miljø. Det muliggjør mer fancy 3D-modellering enn man kunne før. Vi regnet på skipsstøt i Abaqus, og simulerte storm med 3DFloat. For å sørge for at ting stemte mellom modellene, hadde vi Excel-ark og JSON-filer utenfor som beskrev parameterne til modellen. Jeg skrev koden for å bygge opp Abaqus-modellen.
I de første iterasjonene av koden, restartet jeg Abaqus for å kjøre koden min på nytt. Det gikk jeg etter hvert lei av, det var mye venting for å se hva én endring av én linje kode førte til.
Så jeg droppet omstart av Abaqus, og sørget heller for at jeg kunne laste ny kode fra inni Abaqus uten å starte alt på nytt. Da gikk alt drastisk mye raskere enn før.
Jeg fikk mulighet til å open-source en bit av arbeidet med å laste ny Python-kode dynamisk, nå tilgjengelig på github.com/teodorlu/hotload.
Du kan ikke bruke Hotload til å gjøre akkurat hva jeg beskriver her for å få til lynraske modultester, fordi hotload er laget til å lytte på filer, og kjøre kode med effekter på nytt. Det var uansett en spennende opplevelse for meg å se at jeg fikk til å ta kontroll over eget utviklingsmiljø, og at å laste ny kode inn i en kjørende Python-prosess var helt gjennomførbart. Hotload er noe du kanskje kunne skrevet til deg selv, koden er én fil på 300 linjer.
Unntatt tabeller og grafer når man jobber med svære datasett, men da tenker jeg gjerne på det jeg gjør som utforskning og analyse av data mer enn skriving av kode.↩︎
Javascript og React 101
Bakgrunn
Jeg har overhørt flere (spesielt designere) si at de gjerne skulle lært seg litt Javascript og React. Det kan være for å bedre forstå mulighetsrommet, bedre kommunisere med utviklere, lage prototyper, endre enkle ting i koden selv, eller bare av nysgjerrighet.
Uavhengig av hva motivasjonen din er, så kan det virke litt overveldene å finne et sted å starte. Og hvor man skal starte vil jo avhenge helt av hvordan man liger å angripe ting, og hva man kan fra før. De fire viktigste tingene å ha en forståelse for i mine øyne når man lager interaktive nettsider er HTML, CSS, Javascripg og eventuelle rammeverk (f.eks. React).
Personlig mener jeg at rekkefølgen man burde introduseres til de ulike delene er
- HTML (HyperText Markup Language)
- CSS (Cascading Style Sheets)
- JS (JavaScript)
- Rammeverk
Denne artikkelen fokuserer kun på grunnleggende ting i punkt 3 og 4. Å kunne HTML og CSS er ikke et krav for å forstå denne artikkelen, men min oppfordring er likevel å lære seg det grunnleggende der før en begynner på JS og rammeverk.
Målet med denne artikkelen er ikke å være en komplett guide, men mer en kjapp gjennomgang av konsepter jeg mener er viktig å forstå, slik at en har noen knagger å henge ting på og eventuelt noen nye spørsmål en kan stille en utvikler eller Google.
Nyttige resurser
MDN
MDN (Mozilla Developer Network) har veldig god dokumentasjon av HTML, CSS og Javascript med eksempler.
Kommentarer
// Dette er en kommentar. Alt etter // på en linje blir en kommentar og ikke en del av koden.
/*
Dette er en annen måte å skrive kommentarer på.
Den egner seg godt hvis du vil ha mange linjer med kommentar siden den har en start og en slutt.
Brukes ofte hvis man har mye kode man vil midlertidig ta bort eller ignorere.
Eventuelt til å dokumentere koden hvis man har mye å si
*/Variabler og konstanter
/**
* var er kort for variabel og er verier som man kan endre på.
* "var" sier at nå lager du en ny variabel.
* myVar er navnet på variabelen.
* Og 1 er verdien den får
*/
var myVar = 1;
/**
* Etter variabelen er laget trenger du ikke skrive "var" lengre når du skal gjøre ting med den
*/
myVar = 2; // Etter du har laget
// const, eventuelt konstant på norsk, er en verdi som ikke skal endre seg. Så nå vil alltid myConst være tallet 2.
const myConst = 2;
myConst = 3; // <- Dette er ikke lov og vil krasje, siden det er en konstant og ikke en variabel. Datatyper
/**
* !! For enkelhetsskyld blir det her en sannhet med modifikasjoner. Om en ønsker en mer teknisk riktig forklaring
* av datatypene til Javascript kan de leses her: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Data_structures !!
*
* De vanligste datatypene i Javascript er Number, String, Boolean, Array og Object
*/
const myNumber = 12;
// myNumber er av typen Number
const myString = "Hei";
// String (tekst) markeres start og slutt med enten ", ` eller '. Dvs de fleste fnutter kan brukes. Forskjellen på dem er tema for et annet kurs
const myBoolean = true;
// Bolske verdier kan enten være true eller false.
const myArray = [12, "Hei", true, myBoolean];
// arrays er enkelt og greit lister. De kan inneholde alle de andre datatypene. Firkantklammer markerer start og slutt, og komma sperarerer elementene i lista
const myObject = { navn: "Iterate", alder: 12, ansatte: ["Meg", "Deg", "Hen"] };
// Objekter kan også inneholde de andre datatypene, men i motsettning til en liste så er alle verdiene i objektet navngitte.
const myName = myObject.name;
// Måten man henter ut en verdi fra et objekt er med å skrive navnet på objektet, punktum, og så navnet på feltet man vil ha. Så her blir myName satt til "Iterate"
/**
* (Warning, litt teknisk info)
* Javascript er "løst typet". Det vil si at variablene og konstantene har strengt tatt en type,
* men man trenger ikke definere den når man lager den, og for variabler så kan den endre seg.
* Dette skiller seg fra feks Java og TypeScript hvor man må si hva slags type en variabel er når man lager den,
* og den kan aldri være noe annet.
*/
var year = 2020; // Her er year et tall
year = "tjuetjue"; // Mens nå ble det endret til å være en tekst (string)
// Detter er fult lov i Javascript, men ikke lov å gjøre i Java, Typescript etc. Å endre på typen til noe på denne måten kan ofte resultere i morsomme bugs, men gir også en frihet. Funksjoner
/**
* Funksjoner defineres som vist under
* function <- sier at dette er en funksjon
* myFunction <- navnet på funksjonen
* () <- det som er inni parantesene definerer hva funksjonen tar i mot når den kalles (vi kommer tilbake til dette)
* { } <- det som er inni krøllparantesene er selve funksjonen
*/
function myFunction() {
}
myFunction(); // etter funksjonen er laget kan den kalles med å skrive navnet etterfulgt av paranteser.
/**
* Men myFunction gjør jo ikke noe som helst. Så la oss se på hvordan man kan lage en funksjon som legger sammen to tall.
*/
function sum(price, tips) { // Denne funksjonen tar inn to verdier når den kjøres. price og tips
return price + tips; // så returnerer den tilbake summen av dem
}
const total = sum(1000, 100); // total blir her da 1100. Merk at siden sum forventer to verdier må vi ha to verdier mellom parantesene når sum kalles
/**
* Funksjoner kan også defineres som en konstant i steden for å bruke function sytaxen.
* Det gjøres med en såkalt "arrow function" (fordi den har en liten pil i syntaxen).
*
* Dette er en veldig vanlig måte å lage funksjoner på i React-verden
*/
const subtract = (price, deduction) => {
return price - deduction;
}
const reducedTotal = subtract(1000, 100); // Her blir da reduced total 900Conditions
// ----------------------------------------------------------------
// Conditions
/**
* Hvis man vil at noe kun skal skje i noen tilfeller kan man bruke if-statements
* Merk at Javascript er litt rar på sammenliginger. Så når man vil sammenligne to ting vil man ca alltid bruke === og ikke ==
* Spør en voksen eller google om du vil vite mer.
*/
if (a === b) {
// do something
} else if (b === c) {
// do something
} else {
// do something else
}
/**
* Ofte i React hvis man skal gjøre enten a eller b (og aldri ha c, d, e,...) så bruker man en litt kortere og mindre lesbar måte å skrive if-else
*/
const y = a === b ? "a er lik b" : "a er ikke lik b";
/**
* Det som skjer over er at man sier at man skal ha en const y,
* og dersom a er det samme som b, så skal y settes til "a er lik b"
* og hvis ikke skal den settes til "a er ikke lik b".
*
* Dette brukes mye i react. For eksempel hvis en venter på data kan man ha noe i duren:
* isDataDoneLoading ? showUI : showSpinner
* For å kun vise UIet hvis man er ferdig å laste
*/🎉 Tada 🎉
Nå kan du Javascript! Eller… i hvert fall nok til å lese en hel del av det!
Imports
For å gjøre kode fra andre filer eller rammeverk tilgjengelig i fila må de importeres.
/**
* Stort sett alle filer med React kode starter med Import React from "react".
* Her sier man essensielt at man skal gjøre React biblioteket tilgjengelig i fila.
*
* Når det bare står import x from "y"; så importerer man ALT som er i "y".
* En annen måte er å skrive import {a, c} from "z";, da henter man bare a og c, men ikke b fra z
*/
import React from "react";
// Her skjønner Javascript at dette er et rammeverk som skal importeres og vet hvor React ligger
import { sum } from "./helpers";
// Her henter vi ut funksjonen sum som vi lagde i stad fra en fil som ligger i samme mappe som denne fila og heter "helpers". "./" betyr "i denne mappa". En annen vanlig syntax å se er "../helpers" som betyr "helpers i mappa ett nivå opp fra denne"React
React er litt forenklet et rammeverk som oversetter JSX til HTML. JSX ligner veldig på HTML, men man har muligheten til å gjøre veldig mye mer dynamiske ting med det.
/**
* Her definerer vi opp en React komponent. En "React komponent" er stort sett bare en funksjon som returnerer JSX.
* JSX er syntaxen for å skrive (nesten)-HTML i Javascript.
*/
const MyReactComponent = () => {
const myName = "Test Testson"
const age = 25;
return (
<div>
<h1>Hello {myName}</h1>
{age > 20 ? <p>Velkommen!</p> : <p>!!! Ingen under 20 slipper inn</p>}
</div>
);
}
/**
* I JSX kan man bruke krøllparanteser til å skrive javascript inni layouten din. Dette er ikke mulig på samme måte i vanlig HTML.
* I eksempelet over bruker vi en if-else for å sjekke om variabelen age er større enn 20, og i så fall vise en velkomstmelling, hvis ikke viser vi en sint melding
*
* Vi putter også "Test Testson" inn i tittelen på sida gjennom en konst. Dette er typisk slik man viser navnet på den innloggede brukeren dynamisk.
*/OLORM-56: Dit og tilbake igjen—TDD, TCR fra en REPL og tilbake til TDD
Når er det lurt å skrive tester? Hvordan skriver man tester? Hvorfor skriver man tester?
Effektiv enhetstesting i praksis er lettest å lære fra noen som har jobbet effektivt med enhetstesting før. Jeg prøver meg alikevel på en en tekst. Mest historiefortelling, bittelitt enhetstesting i praksis. Spenn deg fast!
Som utviklere kan vi oppnå en vanvittig effektivitet ved å kontinuerlig vite om systemet vi jobber på er rødt eller grønt, holde oss på grønn, og bli i flytsonen mens vi skriver kode. Tre teknikker du kan bruke for å komme nærmere flyt når du koder er test-dreven utvikling (TDD), test && commit || revert (TCR) og REPL-dreven utvikling (RDD). Hva betyr disse egentlig? Og hva kan du bruke nå?
I dag får dere høre om min reise fra TDD til TCR og RDD, og tilbake igjen til TDD.

TDD for dimensjonering av armering i betong
Den første kodebasen jeg jobbet på etter endt utdanning regnet ut nødvendig mengde armering per løpemeter for betongdekker i Python. Da jeg tok over koden hadde koden null tester. Jeg ble overrasket over at utvikleren turte å implementere denne logikken uten tester. Hva om utvikleren regnet feil? Da kunne jo bygg bli dimensjonert feil?
Det første jeg gjorde i den kodebasen var å innføre tester.
Jeg gikk svært sakte fram, og sjekket hva koden gjorde i dag. Og jeg snakket med en eldre byggingeniør med cirka 40 års erfaring med dimensjonering av betongkonstruksjoner. Sammen bygde vi en forståelse for hva koden skulle gjøre.
Etter at vi hadde innført tester i koden, var det tryggere for meg å endre koden. Testene lot meg sove godt.
Folk legger mange ting i testdreven utvikling, kjent som TDD (fra Test-Driven Development på engelsk). Én av definisjonene er at når du koder, gjør du følgende:
- Skriv en ny test som vil bli grønn når du har implementert noe ny kode
- Skriv kode som gjør at testen blir grønn på enklest mulig vis
- Observer at testene er grønne, eventuelt gjør at testene blir grønne
- Rydd i koden så det er tydelig hva koden gjør (kjent som “refactoring” på engelsk).
Man må ikke nødvendigvis skrive test før implementasjon. Men hvis du har tester på koden din, har du bedre kontroll på hva koden gjør. Da er det lettere å rydde i koden, og utvide koden til å gjøre nye ting.
TCR med Elm
Elm er et vakkert, ryddig, lite programmeringsspråk for å lage webapper. Elm-guiden er den beste introduksjonsguiden til et programmeringsspråk som jeg noen sinne har lest. Jeg synes Elm var så bra at jeg lagde og gjennomførte et kurs i Elm-programmering for barn, og snakket om erfaringene på Oslo Elm Day 2019.
Da jeg startet i Iterate fikk jeg jobbe litt med Lars Barlindhaug på Woolit-kodebasen. Vi skrev Elm sammen, og prøvde TCR. Det passet bra, fordi Woolit er skrevet i Elm, Elm er godt egnet for TCR, og Lars var med på bootcampen der TCR ble funnet opp. Lars skriver om sin opplevelse med bootcampen på How to test && commit || revert.
TCR med Elm var en fryd. Typesystemet til Elm er svært kraftig, og når man programmerer Elm sånn Elm er ment til å bli programmert, er det tilnæmet umulig å innføre feil i Elm. En ting som ofte sies om Haskell (et annet programmeringsspråk) er “if it compiles, it runs”. Hvis det kompilerer, funker det. Min erfaring er at det stort sett stemmer for Haskell, og at det ~alltid stemmer for Elm. Elm har et mer konsistent typeystem enn Haskell som er lettere å sette seg inn i ved å ha færre features. Et eksempel er typeklasser, typeklasser er en løsning for polymorfisk dispatch i Haskell. Les wikipedia.org/wiki/Expression_problem for mer info. Philip Wadler nevnes tidlig i Wikipedia-artikkelen, han er en av personene bak Haskell. Elm har ikke typeklasser. Det gjør Elm-kode lettere å lese og lettere å sette seg inn i enn Haskell-kode.
Lars og jeg satte opp TCR til å kjøre “test” som typesjekk. Vi skrev kode, lagret, og gikk kun framover hvis testene var grønne. Det utfordret meg til å tenke i mindre inkrementer.
Litt senere fikk jeg den samme leksa inn med teskje av å jobbe med Oddmund Strømme. Jeg hadde for vane å endre all koden, og være på rød lenge. Det har jeg nå gått tungt bort fra. Nå foretrekker jeg å holde meg på grønn hele tiden, og gjøre refatoreringer som en strøm av kompatible endringer, før jeg til slutt bytter over på ny implementasjon.
Når man gjør dette på teamnivå, kalles det ofte “trunk-based development”.
Umiddelbar feedback for alle kodebaser med REPL
Jeg foretrekker å bruke programmeringsspråket Clojure når jeg kan velge programmeringsspråk. Det er fordi Clojure er et godt egnet programmeringsspråk for REPL-Driven Development. REPL-Driven Development blir også kalt Interaktiv programmering. Hvis du er nysgjerrig på Interaktiv Programmering, er presentasjonen Stop Writing Dead Programs av Jack Rusher en underholdene introduksjon.
Jeg sporer meg selv av. Interaktiv programmering er å programmere fra innsiden av programmet sitt. I stedet for å endre filer som plukkes opp når man rekompilerer eller restarter i en terminal eller med en file watcher, sitter man med en editor koblet til en REPL, der man kan endre oppførselen til egen kode uten å restarte systemet.
Men! Interaktiv Programmering krever trening og disiplin for å brukes effektivt. Du kan lett ende opp i en tilstand der filenes tilstand på disk ikke reflekterer tilstanden til programmet ditt i minne.
Det problemet hadde jeg aldri da jeg skrev Elm med TCR. Jeg visste alltid med 100 % sikkerhet hver gang jeg lagret at koden min passerte typesjekken. Tilsvarende kunne jeg hatt enhetstester, men det hadde jeg ikke, og det følte jeg ikke at jeg trengte. Hvorfor kan jeg ikke få til det samme fra en REPL?
TCR fra inni en REPL
Så, jeg prøvde meg på å løse problemet. Og jeg fikk til det jeg prøvde! Github-repoet teodorlu/clj-tcr beskriver nå hvordan du kan få til TCR i Clojure.
Trikset er:
- Lag en ny TCR-snarvei i editor som du bruker i stedet for “evaluér uttrykk” og “lagre fil”
- Snarveien gjør følgende:
- Lagre alle filer
- Synkroniser tilstand i filer til tilstanden til den kjørende prosessen i minnet
- Kjør testene
- Reverter hvis testene feiler, commit ellers.
- Hvis synkronsiering av tilstand fra filene til den kjørende prosessen feiler, reverterer vi da også.
Her er Clojure-kode som gjør nettopp dette:
(ns user
(:refer-clojure :exclude [test])
(:require
babashka.process
clj-reload.core
cognitect.test-runner))
(defn reload [] (clj-reload.core/reload))
(defn test []
(let [{:keys [fail error]} (cognitect.test-runner/test {})]
(assert (zero? (+ fail error)))))
(defn commit []
(babashka.process/shell "git add .")
(babashka.process/shell "git commit -m working"))
(defn revert []
(babashka.process/shell "git reset --hard HEAD"))
#_{:clj-kondo/ignore [:clojure-lsp/unused-public-var]}
(defn tcr
"TCR RELOADED: AN IN-PROCESS INTERACTIVE LOOP"
[]
(try
(test)
(commit)
(println "success")
(catch Exception _
(println "failure")
(revert)
(reload) ; In those cases where we revert, we choose to clean up our mess
; -- don't leave the user with a REPL out of sync with their files.
)))Som Oddmund tidligere har sagt om TCR, er dette ikke kode man trenger et bibliotek for å bruke. Tilpass arbeidsflyten til koden og de som skal jobbe med koden.
Så binder du en tastatursnarvei i editoren din til å:
- Lagre alle åpne filer
- Kjøre
user/tcr.
Sånn kan den funksjonen se ut i Emacs Lisp:
(defun teod-clj-tcr ()
(interactive)
(auto-revert-mode 1)
(projectile-save-project-buffers)
(cider-interactive-eval "(clj-reload.core/reload)")
(cider-interactive-eval "(user/tcr)"))Så velger du en tastatursnarvei du vil bruke. For å binde til Option+Enter på en Mac som kjører Doom Emacs, kan du gjøre følgende:
(map! :g "M-RET" #'teod-clj-tcr)TDD 2: Dommedag

Hvis du ønsker å bli en bedre utvikler enn du er i dag, bør du jobbe med folk du har noe å lære av. En av utviklerne jeg mener jeg har noe å lære noe av er Christian Johansen. Han er en dyktig programmerer som lager gode biblioteker, og har lang erfaring med test-dreven utvikling og parprogrammering.
På Babaska-meetup i Mai fikk jeg par/mob-programmere med Christian. Jeg kjørte (satt ved tastaturet) og han navigerte (sa hva jeg skulle gjøre). Og han navigerte ved å fortelle meg at jeg skulle skrive tester. Jeg fikk instruksjoner som “skriv en test som sjekker X” og “fiks koden så testen er grønn”.
Jeg innså at vi fikk mesteparten av verdien jeg har fått fra TCR tidligere med god, gammeldags TDD. Skriv koden så den kan testes. Skriv en test som viser oppførselen du ønsker. Kjør testene kjøre, resultatet bør bli rødt. Skriv kode. Kjør testene, resultatet blir helst grønt. Repeat.
Å jobbe med flinke folk er skummelt. De kan ting som du ikke kan. Du føler deg kanskje dømt for at du ikke er flink nok ennå!
Men personene du jobber med er helst ikke en robot sendt tilbake i tid for å ta livet av deg, men heller en trygg utvikler som både ser hva du kan gjøre bedre, og også ønsker å investere i at du kan bli flinkere! Det er ikke til hjelp at noen sier “du, Teodor, du gjør alt feil, og dette er helt håpløst”. I kontrast er det supernyttig når noen viser hvordan de tenker, og stiller spørsmålstegn til rare ting du gjør som du kanskje ikke trenger å gjøre.
TDD fra inni en REPL
Programeringen med Christian fikk meg til å tenke. Jeg ønsker meg følgende:
- En REPL så jeg kan evaluere uttrykk
- Enhetstester som dekker det jeg bryr meg om
- En måte å vite at koden jeg kjører er i synk med koden som kjører på disk
- En umiddelbar måte å kjøre enhetstestene.
Så jeg skrev meg kode for å gjøre nettopp det i min Emacs:
(defun teod-reload+test ()
(interactive)
(projectile-save-project-buffers)
(cider-interactive-eval "(do (require 'clj-reload.core) (clj-reload.core/reload))")
(kaocha-runner-run-all-tests))
(map! :g "M-RET" #'teod-reload+test)Du kan gjøre omtrent det samme med Visual Studio Code og Calva også:
{
"key": "ctrl+[Semicolon]",
"command": "runCommands",
"args": {
"commands": [
"workbench.action.files.saveFiles",
{
"command": "calva.runCustomREPLCommand",
"args": {
"snippet": "(do (require 'clj-reload.core) (clj-reload.core/reload))"
}
},
{
"command": "calva.runCustomREPLCommand",
"args": {
"snippet": "(flush) #_forces-a-print"
}
},
"calva.runAllTests"
]
}
}Ikke test for å teste, test for å gjøre din egen hverdag bedre.
Jeg skriver ikke tester for testene sin skyld. Jeg skriver tester for meg selv og for de andre utviklerne på teamet mitt. Jeg vil ha et godt utviklingsmiljø lokalt, så jeg kan fokusere på å kode, ikke å stirre på stack traces. Og jeg vil ha kontroll på at koden i produksjon gjør det jeg tror den gjør. Derfor skriver jeg tester.
Når jeg møter en kodebase der README sier hvordan jeg kan kjøre testene, og testene dekker det som er viktig i koden min, blir jeg glad!
Appendix A: les Tolkien!
There and Back Again er også tittelen på en bok som er bedre kjent som Hobbiten. Den liker jeg veldig godt!
—Teodor
OJ-3: Kjøre språkmodeller på egen maskin
De siste par dagene har Ole Jacob og jeg utforsket hvordan vi kan kjøre språkmodeller (LLM-er) lokalt på vår maskin. Det vil si, vi fikk et par dager til å leke med denne teknologien for å se om det kunne bidra til å løse et reelt problem i et prosjekt.
Motivasjonen for å kjøre språkmodellene lokalt bunner ut i:
- Unngå avklaringsrunder og usikkerheter rundt om det er ok å laste opp data til en-eller-annen LLM-leverandør på nett.
- Slippe å styre med å lage bruker eller skaffe API-nøkkel til en eller flere tilbydere av LLM-tjenester.
I min erfaring er disse begrensningene ofte grunnen til at vi legger språkmodel-eksperiment på is allerede før vi har prøvd.
Her kommer derfor en liten oppsummering av hva vi har gjort med lokale LLMer og hva vi tenker om de.
Sette opp og kjøre språkmodeller på egen maskin:
Slik satt vi opp vårt språkmodell på vår maskin:
Kjøre selve språkmodellen
Vi lastet ned Ollama, som er et verktøy for å kjøre LLMer lokalt på maskinen. Man kan tenke litt på Ollama som en runtime for språkmodeller, som kan kjøre og interagere med modellene. Den kommer med et API, som gjør det enkelt for andre programmer å koble seg på.
Ollama kan startes enten ved å laste ned det offisielle
Docker-imaget, eller bare kjøre en enkel
brew install ollama om man vil kjøre den rett på maskina.
Vi gjorde sistnevnte.
For å komme i gang lastet vi ned llama3-8b, som er Meta’s
open-source språkmodell. Med Ollama kan den lastes ned med en enkel
ollama run llama3
Med ollama serve starter Ollama-serveren, som man
eksempelvis kan kalle slik:
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt":"Hva er fordelen med å kjøre språkmodeller lokalt?"
}'Denne spyr den tilbake en response fra din lokale llama3. Her finnes det også biblioteker for å enkelt jobbe med Ollama requester og responser i koden din.
Sette opp et UI for å interagere med språkmodellen
Det finnes også mange med UI-er man kan klone ned og kjøre lokalt for
å få grensesnitt til kjapt interagere med din lokale LLM. Vi valgte å
bruke Dify, som gjør
det enkelt å behandle filer og bygge workflows LLM-er. Denne kjørte vi
også opp lokalt, men her ved å klone ned repoet og kjøre en
docker compose etter å ha fulgt Dify’s
dokumentasjon. Den starter en del greier, bla. en server, en
front-end, en database og en reverse proxy. Her var det litt
konfigurering for å sette riktig port i proxyen, og konfigurere den til
å kalle endepunktet til Ollama.
Dify har også ganske najs funksjonalitet for å importere data og gjøre det mulig å la en LLM å søke i det. Til dette koblet vi på en annen lokal språkmodel for å håndtere embedding. Videre kunne vi bruke denne dataen, og en språkmodell for å snakke med vår lokale språkmodell. Sånn ser det ut i Dify:
Så er det bare å kjøre denne, og chatte med språkmodellen som du ville med en annen GPT.
Knowledge retrieval fra egen maskin
De fleste språkmodeller er trent på utdatert informasjon, og har videre ikke informasjon spesifikk for din bedrift ol. I vårt tilfelle hadde vi en del filer, som vi ønsket at språkmodellen vår skulle kjenne til innholdet i. Til dette bruker vi teknikker som embedding, hvor man kan sende en rekke ulike filer og formater gjennom en annen embedding modell (vi brukte nomic-embed-text). Denne modellen brukte vi til å omgjøre filer til vektorer som kan sendes og tolkes som kontekst av språkmodellen vår. Når vi lagde kontekts kunne vi bla. gjøre mye rart, som å kjøre den på en måte hvor embedding-modellen vår lagde spørsmål-svar kombinasjoner til seg selv. Dette kverna litt på maskina, men tok heller ikke allverdens med tid.
Embedding av tekst er et fundament for å lage det vi ønsket å lage, nemlig en språkmodell som hadde konteksten av våre spesifikke forretningsbehov. Dette er hva som i dag ofte blir omtalt som å Retrieval Agmented Generation (RAG). Ideelt sett kan man da bruke også RAG til å søke i egene greier.
Sidenote om språkmodeller og programmer for å jobbe med disse.
I denne LLM-sfæren virker det som det dukker opp nye modeller og verktøy for å jobbe med de hver dag som går. Det her derfor ikke så mye verdi å bruke for mye tid på hvordan vi har jobbet med disse spesifikke verktøyene på vår maskin. Hensikten er i større grad å vise at de finnes, og hvordan de henger sammen, slik at vi har et bedre grunnlag til å kjapt komme i gang med testing når vi ønser å “gjøre noe med AI”.
Open WebUI er et annet alternativ til UI som jeg synes virker spennende.
Hva ble egentlig resulatet?
Tja. Hittil er det nok ikke superimponerende greier vi har konfigurert opp. Mestparten av tiden gikk med til å finne ut hvor vi skulle starte, og få det til å kjøre ok på vår maskin. Deretter var det å konfigurere data og prompts til å sjekke om denne teknologien faktisk kan løse problemet vårt. Hittil er kanskje ikke resultatene helt der, men det har nok noe med datagrunnlaget, promptingen og den litt mer lettkjørt språkmodellen vi brukte. Her tenker jeg en to be continued… er hensiktsmessig.
Jeg så også nå i ettertid at embedding-modellene vi brukte,
nomic-embed-text stort sett er trent på engelsk tekst, som
kan ha bidratt til at den heller ikke leverte varene skikkelig.
Hva har vi lært?
Det viktigste er at det er ganske rett frem å sette opp en LLM på maskina. Med riktig UI-verktøy kan man også prototype workflowen man ønsker å bruke LLMen i. Vi tenker dette kan gi et godt utgangspunkt til å (1) tørre å eksperimentere med data du ikke føler deg helt komfortable med å sende til himmels, og (2) få oversikt over hvordan du vil koble opp data, LLM og prompts før du begynner å kode det.
Man trenger heller ikke sånn alvorlig mye datakraft for å kjøre de
litt enklere LLMene, så å deploye den til en server eller putte den på
noe shabby hardware kan fortsatt monne til en del oppgaver. Vår
favorittvideo denne uken er til inspirasjon, hvor en svenske har
fylt svak hardware til bremmen med en usensurert
llama3-modell, og gjor den litt usikker.
Se opp for en demo fra oss, og ikke nøl med å spør om du er gira på å teste sjæl.
OLORM-55: Bør du lære deg Vim?
Jeg har skrevet mange ikke-tekniske tekster i det siste. Nå vil jeg skrive en teknisk.
I dag vil jeg adressere om du bør lære deg Vim.
Men jeg vil snakke om Vim ved å ikke snakke om Vim.
| Spesialtilfelle | Generelt spørsmål |
|---|---|
| “Bør jeg lære meg Vim?” | “Bør jeg lære meg ting som ikke umiddelbart gir meg verdi?” |
Det er mange ting du kan lære deg
Kanskje du lurer på slaveri i Libya. Kanskje du vil spille gitar.
Mange kule ting tar tid å lære seg.
Å lære vanskelige ting endrer deg
Når noe går veldig fort å lære kan det bety at læringsopplegget er helt fantastisk og du har hatt en vanvittig læringsfart. Det kan også bety at du egentlig kunne tingen fra før av, og har du har lært en ny måte å uttrykke et konsept du allerede kan.
Det en type vanskelige ting som er vanskelige uten at du egentlig burde trenge å lære deg det. Hvis du sitter og må huske 29 steg for hvordan du prodsetter kode kan det ta lang tid å lære seg, uten at du har lært deg en nyttig, ny ferdighet. Kanskje kunne de 29 stegene vært automatisert bort?
Det finnes en annen type vanskelige ting som er vanskelige fordi de er ting du ikke har gjort før. Du prøver deg, tenker at dette høres interessant ut. Du kaster deg ut i det. Så skjønner du ingen verdens ting. Så føler du ingen mestring.
Da kan du velge én av to ting: du kan avfeie det du prøvde, og sette det som et ikke-mål å lære seg. Eller du kan jekke ned selvbildet. Innse at du har noe å lære. Prøve å nå et enklere mål i samme retning.
Denne typen vanskelige ting endrer deg i læringsprosessen. Du går inn som én person, og går ut som en annen person: en annen person som kan mer. Du føler ikke lenger at det er ukjent, skummelt og vanskelig—det som startet som ubegripelig er nå håndfast. Det har blitt en hammer du kan bruke til ting, uten at du tenker på hvordan du holder hammeren.
Mange vanskelige ting på én gang?
Jeg har noen ganger overvurdert min egen kapasitet til å lære. Jeg setter meg et ambisiøst mål. Så gjør jeg ikke det ferdig, og starter med flere andre ambisiøse mål samtidig! Så blir jeg irritert fordi jeg ikke får framgangen jeg ønsker, og ingen prosessene blir ferdig. De flyter rundt uten at jeg føler at jeg har kontroll på tingene.
Fra dette har jeg lært at simultankapasiteten min for vanskelige ting er én.
Jeg vil ha én vanskelig ting å jobbe med, og noen lette på siden. Da fungerer jeg bra. Hvis jeg har en god dag, jobber jeg på den vanskelige tingen. Hvis jeg har en dårlig dag, jobber jeg på den enkle tingen.
Hva lærer du for tiden?
Hvor står du nå? Hva skulle du ønske at du ble bedre på?
Det er lure spørsmål å stille seg selv! Det er også lure spørsmål å diskutere med en mentor. Når du har tenkt over hva du faktisk ønsker å lære, er det lettere å lære.
Oppfordring: ha én vanskelig ting du jobber med å lære deg
Så, velg deg en vanskelig ting du vil lære! Uttrykk for deg selv hvorfor du vil lære tingen. Si til deg selv hva du vil gjøre når du har har fått kontroll på tingen. Det motiverer!
Så kan du velge å dele målet med andre hvis du vil.
Så, bør du lære deg Vim?
Å lære seg Vim gir null verdi den første måneden. Og null verdi den andre måneden. Men etter hvert snur det, og du er mer effektiv med Vim enn med piltaster og mus.
Jeg estimerer at jeg navigerer og redigerer 10-50 % raskere med Vim-bindings i editoren min enn jeg gjør uten.
Så hvorfor la jeg inn innsatsen? Jeg så en person redigere kode mye raskere enn meg, og tenkte at “hmm, jeg har lyst til å lære det”. Så prøvde jeg av og på ganske lenge før ting satt i fingrene.
Jeg har fremdeles mye å lære om Vim, men nå er de tingene lettere å lære. Jeg er over kneika, og kan lære meg én og én liten ting.
I går lærte jeg meg for første gang find replace, ala
:%s/Vim/Programmering i Zig/g. Da satte jeg av en halvtime,
leste litt manual, og fikk brukt find replace.
Og ikke lær deg Vim fordi noen har sagt det. Velg én vanskelig ting du ønsker å lære. Kanskje noe en person du har sett allerede behersker, da vet du at det er mulig.
Leke, lære, lage har en gang i tiden vært mottoet til Iterate!
—Teodor
Krøll på tidslinja
Vi har et ganske vanlig oppsett der en applikasjon lagrer tidspunkt i en MariaDB, og jeg oppdaga en dag at noen så ut til å ligge i rar rekkefølge.
Kun på én spesiell dag, om høsten. Mellom klokka 2 og 3 på natta. Du kan kanskje gjette dagen? Det er selvfølgelig når vi skrur klokka en time tilbake, den siste dagen av sommertid.
Koden i applikasjonen ser omtrent slik ut:
var created time.Time
// ...
db.Exec("INSERT INTO t(created,id,info) VALUES(?,?,?)", created, id, info)Både applikasjonen og databasen kjører med tidssone satt til
Europe/Oslo. Tiden som skrives (created) er
typisk ganske nært eksekveringstiden, noen sekunder eller minutter før
Now().
Det som skjer er følgende:
0. Applikasjon og database kjører med gitt tidssone (Oslo)
1. Applikasjon oppretter en tilkobling til databasen
som har en tidssone på _sesjonen_ (Oslo)
,------------------------. +------+
INSERT(ts) ---> ( session time_zone:XXX ( ) ---> | DB |
'------------------------' +------+
2. Database-driveren 3. Verdien konverteres
i applikasjonen konverterer fra sesjonens tidssone
gitt tidspunkt til sesjonens til UTC og lagres
tidssone og enkoder og sender verdien (Og oversettes fra UTC
til sesjonens tidssone
ved utlesing)Sesjonens tidssone kan settes av klienten, og arver ellers verdien fra DB-serveren.
Jeg hopper til poenget: Problemet ligger i enkoding av verdien i
kombinasjon med sesjonens tidssone. Tidspunktet enkodes som
2023-10-29 02:30:00[.000000] av driveren.
Med tidssone Europe/Oslo er denne tiden som kjent tvetydig, fordi den
skjer to ganger; først for sommertid, så for vintertid. Enkodingen må
derfor inkludere hvilken av dem det er snakk om.
Så, er det bare driveren som er dårlig? Nei, dessverre er det i MariaDB p.t. ikke mulig å enkode tidssone-info verken som binær¹- eller tekst-verdi (i motsetning til MySQL).
Løsningen er å sette sesjonens time_zone og verdiene
som skrives til en fast tidssone uten sommertid, f.eks. UTC.
Merk at dette problemet ikke er spesielt for Norge. Selv om stadig færre land har sommertid, er det fortsatt ca 70 land som gjenstår, inkludert nesten hele Europa og Nord-Amerika.
Hva kunne vi gjort for å unngå bug’en? Lite gjennomtenkte muligheter:
- Prøve å tenke seg til mulige spesialtilfeller?
- Lese hele MariaDB- og driver-dokumentasjonen?
- ~Lese all kildekoden?~ (urealistisk)
- Teste med alle tidspunkt/permutasjoner?
- Kun bruke ukomplisert tech/features?
- Detekter (tenkte) problemer når/hvis de oppstår?
- QA med eksperter?
Send meg gjerne gode forslag.
—Richard Tingstad
Tillegg: testing av tid
Jeg fant et kult bibliotek jeg kunne bruke for å endre tiden; libfaketime, og lagde meg følgende Dockerfile for å gjenskape tidligere tilstander:
FROM mariadb:11.3
RUN apt-get update && apt-get install libfaketime
ENV TZ=Europe/Oslo \
MARIADB_DATABASE=d MARIADB_ROOT_PASSWORD=r \
MARIADB_PASSWORD=p MARIADB_USER=u
COPY <<EOF /docker-entrypoint-initdb.d/0.sql
CREATE TABLE t ( id INTEGER AUTO_INCREMENT PRIMARY KEY,
ts TIMESTAMP, dt DATETIME );
EOF
COPY <<"EOF" run.sh
[ -n "$START" ] || START=$(date -d '2023-10-29 02:30 CEST' +%s)
LD_PRELOAD=$(find /usr -name libfaketime.so.1) \
FAKETIME=-$(( $(date +%s) - $START )) \
"$@"
EOF
ENTRYPOINT ["sh", "run.sh"]
CMD ["docker-entrypoint.sh", "mariadbd"](¹ “The encoding of the COM_STMT_EXECUTE parameters are the same as the encoding of the binary resultsets.” —Binary protocol)

OLORM-53: Forstå brukeren ved å bli brukeren
Å lage produkter for seg selv er forskjellige fra å lage produkter for andre. Hvis du lager produkter for deg selv, kan du vurdere produktet ved å se om produktet løser problemer for deg. Hvis du lager produkter for andre, må du vite om produktet hjelper brukeren i brukerens kontekst.
Er disse tilnærmingene gjensidig eksklusive, med andre ord, må du velge én?
Jeg vil si nei.
Hvordan forstå brukeren ved å bli brukeren
Du kan løse for begge ved å følge to strategier samtidig:
- Sett deg mer og mer inn i hva brukeren er som du ikke er. For hver ting brukeren gjør som ikke gir mening for deg, spør deg selv hvorfor, og prøv å finne ut hvorfor.
- Lær deg litt og litt av hva brukeren kan.
Da skrenker du gradvis inn forskjellen mellom deg og brukeren. Vurderingene dine om hva produktet bør bli blir bedre og bedre.
Deretter risikerer du å lage noe brukeren ikke klarer å bruke!
Hvis du blir skikkelig god på denne strategien, kan du gjøre jobben til brukeren bedre enn den gjennomsnittelige brukeren. Hvis du da lager produkter for deg selv, blir produktet ikke det brukeren trenger.
Da må du løse for to ting:
- Produktet må gi verdi til brukeren der brukeren er nå.
- Produktet må fasilitere til kontinuerlig læring, så brukeren kan bli enda bedre på jobben sin ved å bruke produktet ditt kontinuerlig.
Anvendelse ved å skrive kommandolinje-programmer
Jeg har bidratt til kommandolinje-programmet Neil. Neil er et program for å legge til Clojure-pakker når du programmerer med Clojure.
For å bidra fulgte jeg to strategier samtidig:
- Gjøre Neil til et bedre verktøy for å løse mine behov
- Gjøre en innsats for å forstå hvordan andre bruker Neil på måter jeg ikke ennå forstår.
Den strategien har jeg opplevd at har fungert svært bra, og jeg har begynt å tenke på denne måten når jeg jobber med andre produkter.
Hvis jeg hadde laget et skriveverktøy for journalister, hadde jeg jobbet kontinuerlig med å gjøre skriveverktøyet bedre egnet for sånn jeg ønsker å jobbe, og for å forstå hvordan journalister bruker skriveverktøy på måter jeg ennå ikke gjør. Deretter ville jeg vært litt varsom med å innføre funksjonalitet som kan bli vanskelig å bruke for journalister — enten fordi den forutsetter forkunnskaper journalistene ikke har, eller fordi funksjonaliteten ikke løser for hvordan jeg bør lære å bruke funksjonaliteten.
Ender’s Game av Orson Scott Card er en kul bok
In the moment when I truly understand my enemy, understand him well enough to defeat him, then in that very moment I also love him. I think it’s impossible to really understand somebody, what they want, what they believe, and not love them the way they love themselves. And then, in that very moment when I love them…. I destroy them.
Så … vi vil jo ikke ødelegge brukerene.
Men hvis vi skal overbevise noen om å betale penger for noe vi har laget er utvilsomt en forhandling. Da er det fint å forstå hvor personen du forhandler med kommer fra.
Sitet er hentet fra boka Ender’s game. Les mer om den på Goodreads: https://www.goodreads.com/quotes/97512-in-the-moment-when-i-truly-understand-my-enemy-understand
Den handler om en åtte år gammel gutt som blir sendt ut i verdensrommet for å bli trent til å kjempe mot romvesner. Jeg synes den er fin!
Fortsatt god morgen!
—Teodor
ITERATE-1: I want to be a product editor
Finally I found a term that feels like home. Listening to Ezra Kleins conversation with Adam Moss yesterday made me think that what my job really is about is finding the right product fit through editing. I never found that the term “product manager” fit me, it sort of denoted a very stringent approach to making a product work. All numbers and structure.
Which is kinda why my design career ventured towards products in the first place, exactly because I missed a greater focus on knowing that I contributed to a better world for users.
Coming from design I often lend an eye to the many great tools in the design thinking toolbox, too. Tools that tend to veer toward creativity and ways to understand what users actually want. The combination is golden.
But, there is also another component to building products that I less often hear about. Much of my work is actually feeling my way into what might fit the end user. Based on numbers and insights, definitely, but often I cannot explain exactly why one solution feels better than the next.
Hence my liking for the term product editor, I guess. Especially from the context Adam Moss talks about editing. With the term “product editor”, it feels like getting an “OK” to using my many years of experience building products, without having to explain everything in detail. I can be more fierce in believing in the vision or our direction, whilst hopefully be better at avoiding design by consensus or pure logic. Which is where I sometimes find myself, not being particularly happy about it.
Perhaps this term will also help our clients understand that making products isn’t purely a numbers game, or a straight puck. It is about vision, execution and measuring impact all at once.
I love Adam Mosses description of the creative process amongst the many artists he has interviewed to find in which ways they make decision when making art. The artists stories are very individual, yes, but they go through a similar top level process. I think we could be better at doing something closer to this. The three steps are (my translation):
- being creative
- judging
- detailing
Being pretty good at the first and last, I find we very often don’t focus specifically on the middle one. This part is absolutely essential to find an emotional fit for users—which is really what we’re always searching for. We want to make products that people love (not accept or like).
I think perhaps we are also terrified at the prospect of someone being offended as we critique their/our work. So, naming this stage as key would potentially make it less of a painful process to really edit our products as we wade through customer insights, hypotheses, ideas and aha-moments. I guess I want the ability to really look at our work, judge it well until we get to the point where we can truly be proud to have created a product that makes people go WOW!
I have now changed my title to product editor.
—Kjersti
OLORM-52: On the balance between design and implementation when we build software
Dette innlegget er krysspublisert til Mikrobloggeriet, originalen ligger på Teodors personlige nettside: https://play.teod.eu/software-design-implementation-balance/
X: “design”? You mean the work designers do?
T: No. I mean software design. I have a beef with the current usage of the word “design”. We’re using it vaguely! I used to do design of steel structures and design of concrete structures. These days I often engage in software design.
I feel like the agile movement inadvertently dragged in an assumtion that design is bad, and writing code is better. I think “don’t do design, write code instead” is a really bad idea.
X: So … Why now?
T: I’m working with two great people. Having a lot of fun. But I feel like we struggle a lot finding a balance between design and implementation. Right now, we talk a lot about implementation details, but not about system design.
X: Ah, I get it! You’re talking about architecture! Software architecture!
T: 😅 I … have a bit of a beef with that word too.
X: why?
T: We software developers took the word “architecture” from civil engineering projects, and I fear that we took the wrong word. In software, we want to talk about the core of our system. Architects can do the start of the work, if what you care about is floor plan utilization, and the civil engineering is trivial. Architects do not build bridges. Architects do not build dams. Architects do not build industrial plants. In those cases, the civil engineers (or construction engineers) hold the “core”.
X: so … which word, then, if architecture is bad?
T: I think the word is “design”. And for systems, “system design”!
X: okay. Man, when you insist on redefining words before you even start speaking, it sometimes rubs be the wrong way. It’s like everything I say is wrong, right?
T: Yeah, I know. Sorry about that. I don’t know of a better way — other than leaning completely into the arts, presenting ideas as theater, dialogue or as novels. Steal from Eliyahu Goldratt’s way of presenting things, perhaps.
X: yeah, yeah. I don’t always have time for that, you know?
T: Yeah, there’s so much f-in stuff. I feel like we could make due with less stuff. But that requires some thinking.
X: So … What was that balance you mentioned? A balance between design and implementation?
T: Right. Thanks. That was where we started.
We spend so much time on implementation and so little time on design. And we’re calling it “agile”. “agile” as an excuse for coding up things when we don’t have any idea why we have to do the things we do. If we slow down, we might get pressure to speed up. It’s lean to do less stuff. But rather than cut the problems we don’t care about, we solve the problems we care about badly!
This is where design comes in. We should know what our goal is. I’m … I’m at a point where I have no interest in writing code unless the goal is clear.
X: what about teamwork? Everyone needs to know what do do, right?
T: Yeah, that’s the hard part. It’s harder to solve real problems than write code. And it’s even harder when you’re a team. So much shared context is needed.
X: So, what do we do?
T: I’m discovering this myself as I go along. I’ve had success with two activities.
One activity is pair programming. This one is hard. Knowing when to focus on design and when to focus on implementation is hard. I think great pairing is something you have to re-learn every time you pair with someone new. Without trust, this will simply fail. And that trust needs to go both ways. I need to trust you, and you need to trust me.
Another activity is to use a decision matrix to compare approaches to solve a problem. A decision matrix lets you do clean software design work without getting stuck in all the details.
X: How should I learn pair programming?
T: Ideally, you get to pair with someone who is good at pair programming. I had the chance to pair with Lars Barlindhaug in 2019 and Oddmund Strømme in 2020. From Lars, I learned that it’s better to organize your code into modules where each module solves a problem you care about. From Oddmund, I learned that I could work in smaller increments.
If you do not have someone you can learn pairing from on your team, watch Magnar Sveen and Christian Johansen pair from their youtube screencasts: https://www.parens-of-the-dead.com/
X: And … those decision matrices?
T: Watch Rich Hickey explain decision matrices in Design in Practice. Then try it out with your team!
Thank you to Christian Johansen for giving feedback on an early version of this text.
—Teodor
KIEL-2: Spekulative scenarier
KIEL-1 var en introduksjon til tematikken om hvorvidt AI-verktøy hører hjemme i klasserommet. KIEL-2 omhandler neste fase, der jeg utforsker tematikken gjennom å lage noe selv.
Hvorfor gjør jeg dette?
Dette prosjektet er selv-initiert og drives av en ganske heftig magefølelse. Jeg opplever problemstillingen som høyaktuell, og som designer og teknologi-formidler kjenner en sterk dragning mot å bidra konstruktivt inn i diskusjonen. Diskusjonen gjorde jeg kort rede for sist, men jeg er derimot ikke helt sikker på hva det vil si å “bidra konstruktivt” inn i den. Jeg erfarte at min forrige presentasjon om eget utforskende arbeid med AI-verktøy syntes å resonnere med mange, og en del folk kommenterte at de ikke har “tenkt på AI på den måten før”. Dette gjaldt spesielt personer som ikke er noe særlig interessert i AI, noe som er en stor seier i mine øyne. Jeg tror en stor del av utfordringen vi står overfor handler om å få med flere stemmer blant de uinteresserte og de skeptiske. Ikke for å overbevise om at Silicon Valley har rett. Tvert i mot; for å hjelpe denne delen av befolkningen å ytre seg, i en ekstremt hurtig og mektig teknologisk utvikling som allerede påvirker livene deres i aller høyeste grad. Poenget er at det er ganske håpløst å ytre seg, enten det er skeptisk eller optimistisk, om det man ikke vet noe om.
Heldigvis vet egentlig ingen så veldig mye, fordi alt er jo så nytt! Derfor trenger (og burde) ikke mitt oppdrag å handle om å lære opp, si, den eldre garde i hvordan man bruker AI-verktøy som likevel blir utdatert ila. et par måneder, men heller å skape rom for samtaler om hva som er mulig, hva vi burde unngå, og hva vi ønsker oss fra en slik teknologi. Jeg håper at en slik tilnærming kan bidra til mindre fokus på verktøyene og produktene, og mer på problemene de skal løse.
Spekulativ design
Dette rommet for samtale om fremtiden, kan skapes ved hjelp av noe som kalles spekulativ design. Måten man snakker om spekulativ design kan minne om måten man snakker om sci-fi-filmer. ‘Hva hvis aliens kom på besøk?’ ‘Hva hvis 2. verdenskrig aldri skjedde?’ ‘Hva hvis teknologi fikk bevissthet?’ Spekulativ design skiller seg fra sci-fi-historier ved at det presenterer en alternativ virkelighet gjennom konkrete produkter, tjenester eller interaksjoner designet for nettopp den alternative virkeligheten. Bare små ‘snapshots’; resten må mottakeren selv tenke seg til, og undre seg over.
Her en en beskrivelse fra boka Speculative Everything av design-lærerne og -professorene, Anthony Dunne og Fiona Raby;
…the idea of possible futures and using them as tools to better understand the present and to discuss the kind of future people want, and of course, ones people do not want. …They usually take the form of scenarios, often starting with a what-if question, and are intended to open up spaces for debate and discussion; therefore, they are by necessity provocative, intentionally simplified, and fictional.
Jeg har vært fascinert av spekulativ design lenge, men det er først i det siste at jeg har oppdaget effekten av et annet aspekt; nemlig humor. Dragningen mot å bruke nettopp spekulativ design i dette prosjektet startet med en fyr på Instagram ved navn Soren Iverson. Iverson lager og deler én idé hver dag, alle bestående av et skjermbilde av en iPhone med et fiktivt UX-design, eller som han selv beskriver dem, absurd versions of the apps we interact with on a daily basis. Høydepunkter **inkluderer en Spotify-funksjon som gjør julemusikk utilgjengelig utenfor juletida (Fig 1), en Tinder-funksjon som ber deg svare på hvorfor du sveipet til venstre (Fig 2), og annonser som sniker seg inn der du ikke skulle tro det var mulig (Fig 3). Idéene får meg til å humre, før de får meg til å tenke. Og plutselig begynte jeg å lure på om denne fremgangsmåten kunne benyttes til å si noe nytt om bruk av AI i skolen.
How to reverse engineer a joke.
Jeg startet med å prøve å forstå hvordan vitsene til Iverson var bygd opp. Et viktig aspekt er at han legger seg veldig nært interaksjonene og brukergrensesnittene vi allerede kjenner til. Idéene er absurde, men de er samtidig ekstremt troverdige. Denne subtiliteten gjør det lett for mottakeren å se for seg scenariet. Noe annet man legger merke til er hvordan idéene veksler mellom å beskrive fine og fargerike scenarier, mens andre er kikkehull inn i en dystopisk og superkapitalistisk virkelighet. Samtidig forener humoren disse to ytterpunktene; dette er jo bare jokes på Instagram. Jeg synes denne dualiteten passet godt med problemstillingen min; de fleste er jo både litt redde for, og litt fascinerte av AI. Med en slik fremgangsmåte kunne jeg kommunisere både skepsis og optimisme, men hele tiden jobbe med grensesprengende idéer. Høres jo gøy og nyttig ut samtidig det!
Jeg inviterte til en workshop med noen av mine permitterte design-kolleger. Etter å ha introdusert Soren Iversons idéer, ba jeg dem hjelpe meg å applisere samme tankegang på AI-i-skole-problemet. Vi gikk i gang med å skrive en haug med lapper som beskrev scenarier fra videregående skole. Skulke skolen, jukse på prøver, innlevering kl. 23.59, å ikke få nok søvn, å bli distrahert i klassen, det sosiale hierarkiet, friminutter og lunsj. Vi trakk deretter hver vår lapp, og begynte å tegne UX-skisser for hånd. Det bør nevnes at vi valgte å utvide perspektivet fra AI i klasserommet til teknologi i skolen, fordi det er scenariene som er interessante å fokusere på, ikke verktøyene i seg sev, og det føles noen ganger som en tvangstrøye å skulle dytte AI inn i alt mulig. Jeg tror det er mulig at denne voldsomme interessen / hypen for ny teknologi i den offentlige diskursen, kan overskygge hva vi prøver å oppnå med den. Selve begrepet AI er bestandig i fokus, og jeg tror det kan hindre oss i å tenke klart.
Idéer og scenarier.
Idéene som kom ut av workshoppen traff over forventning, særlig fordi de faktisk var morsomme. Høydepunkter inkluderer:
- Lærerens nøyaktige posisjon i sanntid på mobilen. (Fig 4)
- Funksjonalitet som måler allmenntilstand og søvnmengde, og dermed gir en vurdering på hvorvidt du er i stand til å lese (dårlig) eksamens-tilbakemelding på nåværende tidspunkt. (Fig 5)
- Vipps-funksjon som gjør at foreldre kan vippse med forbehold om godt resultat på skolen. Pengene låses opp ved skanning av tilfredsstillende karakter. (Fig 6)
Jeg tok noen av idéene, og begynte å tegne dem ut i troverdig oppløsning; bl.a. Vipps-idéen (Fig 7). Som nevnt gjør de kjente brukergrensesnittene det lettere for mottaker å koble seg på fiksjonen, og de er samtidig enklere å komme i gang med enn de mer løsrevne konseptene.
Et mer løsrevet konsept jeg endte opp med å tegne ut er et slags digital klasseromsvakt (Fig 8), som følger med på telefonen din om du gjør noe du ikke skal i timen, gir deg en varsel, og setter i gang en nedtelling før man får anmerkning.
Timeplan i Ruter (Fig 9) er langt mindre dystopisk, og gjør det muligens lettere for en trøtt elev å komme seg på skolen.
Side note: en motivasjon for meg i dette prosjektet er å terpe på UX-skills. Å kopiere det visuelle språket til f.eks. Ruter kan sikkert gjøres på hundre måter, og her har jeg bare prøvd meg fram. Det er rimelig tilfredsstillende å flytte på piksler til mitt kunstneriske bidrag smelter inn i det opprinnelige skjermbildet. Tålmodigheten som trengs er noe jeg vanligvis mangler, men nå har tid til. Derfor befinner jeg meg nå midt i en bratt og spennende læringskurve.
Det hadde vært nyttig å vite mer om hvilke verktøy norske vgs-elever bruker ila. skoledagen. I mellomtiden gjetter jeg på at de skriver oppgaver i programmer som Google Docs, og gjorde dermed et par skisser fra et scenario der eleven jobber med innlevering på maskinen sin. Disse tar i tillegg for seg AI-teknologi; den første advarer, den andre oppmuntrer.
Fig 10: Advarsel i Google Docs om bruk av AI i oppgaveskriving. Google har (IRL) kjørt ut en testversjon av en AI-knapp i dokumentet hvor det står “Hjelp meg å skrive”. I mitt scenario dukker det opp en beskjed om man trykker på denne, bl.a. med advarsel om “KI-prikk” på vitnemålet. Jeg ser for meg en skolekultur der man får fordeler, f.eks. når man søker studier, dersom man evner å bruke sin egen stemme, uten innblanding av AI.
Fig 11: AI-chat integrert i innleverings-dokument, hvor eleven kan snakke med relevante historiske personer, i dette tilfelle filosofer fra opplysningstiden. Idéen om å rigge chat-boten sånn at den svarer som en kjendis, fiktiv karakter eller historisk personlighet er ikke ny, men det er interessant å drømme om et brukergrensesnitt løsrevet fra en dedikert chat-applikasjon. Her er det er mye interessant å utforske, og jeg tror ikke det er lenge før vi ser AI-brukergrensesnitt som er langt mer fleksible enn de er i dag.
Hva er veien videre? Tegne ut flere fiktive interaksjoner med teknologi i skolekontekst, og formidle dem på en eller annen måte.
Ønskelig påfyll:
- Reaksjoner / tilbakemeldinger på idéene, og gjerne diskusjoner.
- Innsikt om teknologi som brukes av norske vgs-elever, og ansatte i skolen.
- Eksempler på flere AI-verktøy og alternative måter å bruke dem på, til inspirasjon.
Jeg leker også med tanken rundt å gjøre dette til noe
“community-based”; altså åpne opp for at flere bidrar inn med sine idéer
og ferdigheter. Kanskje kan man se for seg en anonym-Instagram-bruker
drevet av en hel haug med designere fra ulike hjørner av bransjen, som
tegner og deler troverdige og øye-åpnende scenarier hver dag.
Linjer i fil A som ikke er i B
Hvis du har to tekstfiler, A og B, hvordan finner du alle linjene i A som ikke er i B?

(Et eksempel-brukstilfelle er å filtrere ut linjer som allerede er behandlet.)
Mitt goto-verktøy er grep 👇
grep
grep -F -f B -v < A
# search a file for a pattern
#
# -F, --fixed-strings
# Match using fixed strings. Treat each pattern specified as a string
# instead of a regular expression. (-F is specified by POSIX.)
#
# -f pattern_file, --file=pattern_file
# Read one or more patterns from the file named by the pathname
# pattern_file. Patterns in pattern_file shall be terminated by a <newline>.
# (-f is specified by POSIX.)
#
# -v, --invert-match
# Select lines not matching any of the specified patterns.
# (-v is specified by POSIX.)grep er generelt veldig rask, men med stor
pattern_file så går det sakte. Hvis filene kun består av
ASCII kan vi bruke prefiks LC_ALL=C grep for å øke ytelsen
noe, men det hjelper ikke så mye. Hvilke andre alternativ har vi?
hash set
Ett nivå lavere enn å kjøre en database er å bare huske linjene i minnet vha. f.eks. Python, Node.js eller awk:
awk 'BEGIN{
while(getline < "B") seen[$0]++
close("B")
}
!seen[$0]' < AAwk består av ett eller flere pattern{ action } der
BEGIN er et spesielt pattern som kjører før input (A)
behandles, og !seen[$0] får default action
{ print $0 } siden ingen er angitt. ($0 er ei
tekstlinje.)
Hvis du ikke vil holde hele B i minnet eller bruke et ekstra programmeringsspråk finnes det noen flere enkle kommandoer. 👇
join
Hvis A og B har én identifiserende kolonne
(eller ett ord), kan vi bruke sort og
join:
sort -oA A
sort -oB B
join -v 1 A B
# join - relational database operator
#
# The join utility performs an “equality join” on the specified files and
# writes the result to the standard output. The “join field” is the field in
# each file by which the files are compared. The first field in each line is
# used by default. There is one line in the output for each pair of lines in
# file1 and file2 which have identical join fields. Each output line consists
# of the join field, the remaining fields from file1 and then the remaining
# fields from file2.
#
# -v file_number
# Instead of the default output, produce a line only for each unpairable
# line in file_number, where file_number is 1 or 2.Hvis du ikke vil tenke på kolonner, kun hele linjer, er siste kommando perfekt. 👇
comm
comm -2 -3 A B
# compare two sorted files line by line
#
# three text columns as output: lines only in file1, lines only in file2, and
# lines in both files.
#
# -1 Suppress the output column of lines unique to file1.
# -2 Suppress the output column of lines unique to file2.
# -3 Suppress the output column of lines duplicated in file1 and file2.Denne visste jeg ikke om før nylig, men den er like grunnleggende som
grep — fra 1973! (De nyere join og awk er “bare” fra
1979.)
Jeg synes disse gamle verktøyene er kjempefine og nyttige den dag i dag.
Har du andre måter å filtrere ut eksisterende linjer? Jeg vil gjerne høre.
— Richard Tingstad
KIEL-1: Kunstig Intelligens - Ekte læring.
Som permittert med tid til egne prosjekter, begynte jeg å fundere hvordan Kunstig Intelligens (KI…) kan bidra til Ekte Læring (…EL) i skolen. Dette er en pågående og het debatt i samfunnet generelt, og frontene er tilsynelatende meget vanskelig å forene.
På den ene siden er optimistene med en total overbevisning om at man må følge med i tiden, og at vi MÅ ta i bruk disse verktøyene nå for å kunne forstå dem. Dessuten bringer teknologien med seg mange fordeler for tilrettelagt læring, og interaktivitet.
På den andre siden er skeptikerne som mener at AI ikke har noe i skolen å gjøre, og vil blant annet føre til mer juks og mindre selvstendig tenkning. Det bidrar også til problemet med generelt høy skjermbruk (mye stimuli og passivitet) over hele linja, i tillegg til GDPR-utfordringer.
Mange, meg selv inkludert, tror at en god tilnærming finnes et sted i midten: AI er kommet for å bli, utvikler seg meget raskt og er noe vi burde forholde oss aktivt til, ikke avskrive. Samtidig virker enkelte scenarioer skremmende, og høyst uønsket sett i sammenheng med barns læring: for eksempel at lærerens jobb med å skille mellom hva som er ekte og hva som er AI-generert blir umulig. Vi kan ikke havne der hvor elever kan få toppkarakterer ved å bli gode på snarveier; dette har ingenting i skolen å gjøre. Derfor burde vi heller bruke energien vår på å tenke ut måter AI kan støtte læring.
For å forstå mer, intervjuet jeg forrige uke en ungdomsskolelærer fra Asker. Jeg visste at vedkommende er en teknologi-optimist, og at han bruker diverse AI-verktøy i sin undervisning. Kort sagt hadde denne læreren opplevd verktøyene som nyttige for undervisningen, og at mye handlet om å rigge chatbots slik at de ikke kunne gjøre hva som helst, men bistå innenfor konkrete rammer knytta til et spesifikt fag. Verktøyene han brukte var forøvrig “hjemmesnekra”, bl.a. for å unngå GDPR-problematikk med OpenAI. Nærmere bestemt må studentene, som sitter med hver sin Chromebook i timen, logge inn med en bruker. Det er blant først og fremst denne innloggingen som må være personverns-beskyttet.
Med de hjemmesnekrede løsningene følger et behov for veiledning. Dette gjøres bl.a. i form av en digital manual (a la denne) inndelt etter informasjon til lærere, foreldre og barn. Pedagogikken og informasjonsflyten her er jeg veldig nysgjerrig på; i hvilken grad hjelper veiledningen dem som aldri har vært borti slike verktøy?
Etter litt leting på nett fant jeg en rekke “klasserom-spesialiserte” AI-produkter på det amerikanske markedet. I klassisk tech-startup-stil ser disse eksemplene selvfølgelig langt mer attraktive ut enn hva læreren i Asker hadde snekret sammen, med svært glossy landingssider og store lovord. Det er ikke dermed sagt at de fungerer bedre; om det er noe jeg har lært fra mitt utforskende arbeid med AI så er det at man må lage mye av moroa selv. Ja, GPT er gøy out of the box, men det er først når du tilpasser den dine behov at den blir virkelig nyttig. Uansett, fra et design-perspektiv er det interessant å se hvordan man (disse tech-startupsa) pakketterer og ikke minst selger inn AI-verktøy til klasserom. Et innsalg i seg selv er: Dette verktøyet kan ikke brukes til juks!
**Produktene kalles forøvrig AI Tutors. Hva blir det på norsk tro? KI-hjelpelærere? Og hvem blir den første norske startupen til i tilby noe sånt? Det er nok like rundt hjørnet.
To eksempler:
- Synthesis fokuserer på matte, og fletter gamification sammen med en AI som gir “tailored feedback”. Ganske rå innsalgs-film,
- Khanmigo lover å ikke bare gi svar, men å guide eleven til å finne dem selv. En TED-talk fra Khan Academy handler om hvordan AI could save education.
Selv om noen foreldre rapporterer om gode erfaringer med bruk av de hjelpsomme chatbotene, finner jeg ved videre søk (Reddit) at markedsføringen tegner et bilde som ikke nødvendigvis speiler virkeligheten. Uten å gå inn i detaljer, så er det fortsatt veldig lite bevis på situasjoner der AI + klasserom skaper ny verdi.
Så hva skal jeg bidra med? Det får bli neste KIEL.
OLORM-50: For mye opsjonalitet
Hvor mye bør man eksperimentere i bredden? Når bør man smalne sammen?
I design thinking snakkes det om expandering (expand) og kontrahering (contract).
- Under ekspandering dyrker vi forskjeller. Vi trenger først å finne muligheter før vi kan begynne å gjøre ting.
- Under kontrahering utforsker vi én retning. Vi tar en løst formulert idé og gjør den ekte.
Så hva er opsjonalitet? En opsjon er noe du kan velge å gjøre. Mye opsjonalitet er bredt handlingsrom. Du har mange ting du kan velge å gjøre. Lite opsjonalitet er smalt handlingsrom. Du har én eller ingen ting du kan gjøre.
Symptomer på for lite opsjonalitet
Når det gjøres én bred beslutning tidlig og den følges slavisk, hvordan vet man at man gjør rett ting? I produktsammenheng snakkes det om “outcome over output”. Målene du setter bør være effekter du vil oppnå, ikke ting du skal gjøre. Hvorfor? Fordi målet er ikke at det gjøres jobb. Målet er å løse problemer!
Når jobben blir målet, er typisk problemet for lite opsjonalitet. I stedet for å løse problemer, gjør vi oppgaver.
Symptomer på for mye opsjonalitet
Så, hva skjer når du får for mye opsjonalitet?
- Du tenker på mange forskjellige problemer som ikke har så mye med hverandre å gjøre.
- Ting faller i glemmeboka.
- Du får ikke fullført ting du begynner på.
- Du føler at du mister oversikt.
Begrens work in progress!
Når du har for mye opsjonalitet, må du begrense work in progress. Du må begrense hvor mange ting du driver med samtidig. Det gjør du ved å si nei!
Men du trenger ikke si “nei, det kommer jeg ikke til å gjøre, det du spør om er dumt”. Fordi det er ikke det du mener. Det du mener er å si at du ikke har kapasitet til å begynne å se på dette nå.
Kutt scope
For mye opsjonalitet for jobben du gjør betyr at du gjør for mange ting på én gang.
Det kan også være for mye opsjonalitet i produktet du lager.
I Mikrobloggeriet har vi støtte for temaer. Du kan scrolle nederst på forsiden og velge tema. Det synes jeg er gøy! Vi har laget oss handlingsrom til å eksperimentere med temaer.
I dag lager denne eksperimenteringen friksjon. Olav og Neno har jobbet med stilsetting av nettsiden. I det arbeidet har ikke temasystemet vært til nytte—det har vært til hinder.
Hva kan vi gjøre? Én mulighet er å slette temasystemet og begynne på nytt.
I kodespråk er temasystemet en dårlig abstraksjon. Temasystemet skulle abstrahere spesifikke temaer vekk fra generelle regler. I praksis er abstraksjonen for lite fleksibel, fordi Neno og Olav ikke får gjør det de ønsker.
Har du passe mye opsjonalitet i hverdagen?
Hvis du har for lite opsjonalitet kan du utfordre oppgaver og spørre hvorfor dette skal gjøres. Hvis du har for mye opsjonalitet, kan du si nei til jobb eller kutte variasjon i produktet du lager.
Vil du ha mer lesestoff?
Les Let a 1,000 flowers bloom. Then rip 999 of them out by the roots. av Peter Seibel. Den er bra!
—Teodor, 2024-02-09
VAKT-1: La forskjeller blomstre!
Da jeg startet i Iterate, fikk jeg vite at her lager vi våre egne verktøy. Da fikk jeg forventninger. “Åja, flott, så jeg kan faktisk påvirke verktøyene jeg bruker? Det høres bra ut!” I praksis var det ikke helt som jeg forventet. Kodebaser er kodebaser; bare fordi man har kildekoden er det ikke nødvendigvis trivielt å endre. Jeg har gjort én kodeendring som andre i Iterate bruker minst én gang i måneden: at knappen i timeføringssystemet viser hvilken måned det er man lukker når man lukker måneden.
Kontroll over egne verktøy og kontroll over egen arbeidsflyt har vært et viktig prinsipp og en kilde til inspirasjon for Mikrobloggeriet. Mikrobloggeriet bør være et verktøy jeg kan være stolt av—et verktøy jeg vil bruke selv. Derfor er skriveflaten filer i Git du kan endre med din egen editor. Ikke en shitty web-editor du hater å redigere i!
Men hva med de andre? Hva med andre sine preferanser? Hvordan kan andre få den samme gleden i bruken av verktøyene som jeg har fått?
Dette er løsbart!
Kode handler ikke om å sette alt i samme system så alle skal gjøre det samme. Kode bør organiseres så den er effektiv å jobbe med. Da bør du kunne velge å følge systemet eller ikke. Samtidig bør det være plankekjøring dersom man ønsker å følge veien de fleste følger.
Neno lagde i desember mikrobloggen URLOG. Her utfordrer han status quo for mikroblogger på Mikrobloggeriet. Han vil ikke skrive, han vil lede oss til andre plasser på Internett der vi kan bli overrasket.
Denne typen konsepter har fra dag én vært det jeg ønsker å se, og er grunnen til at vi gjør routing sånn vi gjør.
Her er routing-tabellen:
(defroutes app
(GET "/" req (index req))
;; STATIC FILES
(GET "/health" _req {:status 200 :headers {"Content-Type" "text/plain"} :body "all good!"})
(GET "/vanilla.css" _req (css-response "vanilla.css"))
(GET "/mikrobloggeriet.css" _req (css-response "mikrobloggeriet.css"))
(GET "/reset.css" _req (css-response "reset.css"))
(GET "/urlog.css" _req (css-response "urlog.css")) ;; NENO STUFF
;; THEMES AND FEATURE FLAGGING
(GET "/set-theme/:theme" req (set-theme req))
(GET "/set-flag/:flag" req (set-flag req))
(GET "/theme/:theme" req (theme req))
;; STUFF
(GET "/feed/" _req (rss-feed))
(GET "/hops-info" req (hops-info req))
(GET "/random-doc" _req random-doc)
;; OLORM
;; /o/* URLS are deprecated in favor of /olorm/* URLs
(GET "/o/" _req (http/permanent-redirect {:target "/olorm/"}))
(GET "/olorm/" req (cohort-doc-table req store/olorm))
(GET "/o/:slug/" req (http/permanent-redirect {:target (str "/olorm/" (:slug (:route-params req)) "/")}))
(GET "/olorm/:slug/" req (doc req store/olorm))
;; JALS
;; /j/* URLS are deprecated in favor of /jals/* URLs
(GET "/j/" _req (http/permanent-redirect {:target "/jals/"}))
(GET "/jals/" req (cohort-doc-table req store/jals))
(GET "/j/:slug/" req (http/permanent-redirect {:target (str "/jals/" (:slug (:route-params req)) "/")}))
(GET "/jals/:slug/" req (doc req store/jals))
;; OJ
(GET "/oj/" req (cohort-doc-table req store/oj))
(GET "/oj/:slug/" req (doc req store/oj))
;; GENAI
(GET "/genai/" req (cohort-doc-table req store/genai))
(GET "/genai/:slug/" req (doc req store/genai))
;; LUKE
(GET "/luke/" req (cohort-doc-table req store/luke))
(GET "/luke/:slug/" req (doc req store/luke))
;; NENO
(GET "/urlog/" req (urlog/urlogs req))
(GET "/urlog/:slug/" req (urlog/doc req store/urlog))
)Først litt statiske filer, temasystem, RSS-støtte, knapp for å gå til tilfeldig side, la oss kalle det funksjonalitet. Under er det manuelle oppføringer for hver kohort. Det gjør at vi har null implisitt kobling mellom kohorter. Og det er lett å støtte gamle URL-er (Cool URIs don’t change).
Det var det jeg ville si for nå. Tusen takk til Neno for at du ikke bare snakker om ideer du har, men gjennomfører.
—Teodor, 2024-02-09
Send signaler til kommando
Jeg kjører for tiden en kommando som tar lang tid og inneholder en
sleep for å ikke overvelde systemer den kaller:
cat big | while read in
do
echo $in
sleep 1
done | processUlempen med statiske, langlevde kommandoer er at endringer krever omstart.
Jeg ville justere sleep 1 under kjøring, og en måte å
gjøre dette på er å bruke signaler:
cat big | (
trap 'i=$((i+1))' USR1
trap 'i=$((i-1))' USR2
sh -c 'echo Signal $PPID' >&2
i=1
while read in
do
echo $in
sleep $i
done) | process(Visste du at du kan blande imperativ kode inn i en pipeline sånn?)
Hvis denne skriver ut Signal 139 kan jeg gjøre:
kill -s USR1 139 # inkrementer $i
kill -s USR2 139 # dekrementer $i—Richard Tingstad
P.S. Inspirert av (GNU) xargs.
OLORM-48: Løs kobling
Jeg har trampet høylytt og sagt at du er ansvarlig for å bygge delt forståelse av hva som er bra, innenfor din ekspertise. Jeg er også ansvarlig for å bygge delt forståelse av hva jeg synes er bra.
Så hva er god kode?
God kode er løst koblet
God kode er delt i moduler der hver modul er løst koblet fra andre moduler.
Men hva er løs kobling?
Jepp, det er det gode spørsmålet. Jeg vil ikke komme med en formell definisjon av hva løs kobling er; jeg vil heller komme med noen eksempler.
| tettere koblet | løsere koblet |
|---|---|
package.json har 20 avhengigheter |
package.json har 16 avhengigheter |
| modul A bruker 6 funksjoner i modul B | modul A bruker 3 funksjoner i modul B |
| modul A bruker modul B, modul B henter tilstand i applikasjonen selv | module A bruker modul B, all informasjon sendes som eksplisitte funksjonsparametre |
| for å jobbe på en app, kan jeg kjøre kun koden jeg bryr meg om | for å jobbe på en app må jeg starte 7 ting jeg ikke vet hva er |
| enhetstestene krever at databasen kjører | enhetstestene krever ikke at databasen kjører |
| jeg må ut og teste i test- eller prodmiljøer for å finne ut om det funker | jeg kan kjøre det jeg bryr meg om lokalt |
Liksom-løs kobling som egentlig er tett kobling
Å splitte kode i noe kode en plass og noe kode en annen plass gir oss ikke nødvendigvis løsere kobling. I verste fall har vi like tett koblet kode, som nå er to plasser. Da har vi alle problemene vi hadde før (koden er fortsatt tett koblet), men enda et problem: vi må huske på at noen av koden er et annet sted, og vi må vite hva som skjer der for å få gjort noe.
Det er vanskelig å sikre løs kobling
Da jeg først hørte James Reeves si noe ala “developers develop a smell for coupling and learn to avoid it”, skjønte jeg ikke hva han mente. På det tidspunktet hadde folk betalt meg for å skrive kode i nærmere fem år. Hva betyr det, liksom? Hva har det å si?
I dag ser jeg på kobling som en tung ryggsett. Hver kobling koden din har til annen kode er en stein i ryggsekken. Det er tyngre å gå når ryggsekken er full av stein!
Ekstrem kobling: sykliske avhengigheter
Hvis modul A kaller på modul B, og modul B også kaller tilbake på modul A, er ting så ille som de kan bli! Du kan nå verken endre A uten å endre B, eller endre B uten å endre A. Her er to ting du kan gjøre:
Slå sammen til én modul. Hvis begge modulene bruker den andre, har du ikke fått fordelene med å splitte i moduler. Så gå videre med én! Kanskje dette burde være én modul. Skal du bruke gjensidig rekursjon (“mutual recursion”), må begge funksjonene kjenne hverandre (med mindre du bruker en tilstandsmaskin eller noe sånt, men det har ikke jeg hatt behov for å gjøre i praksis ennå.)
Splitt koden i fire. Trekk først ut grensesnittet mellom modul A og modul B. Putt grensesnittet i modul G. Skriv nå modul A og modul B om til å kun være avhengig av grensesnittet. I statiske språk blir dette typer, og/eller “interfaces” (Go, java), “traits” (Rust) eller typeklasser (Haskell). Skriv en siste hovedmodul H der du bruker både modul A og modul B. Til slutt får du disse avhengighetene:
H -> A H -> B A -> G B -> GHovedmodulen (H) heter ofte “main”, og vet det den må vite for å starte applikasjonen.
For å få løsere kobling, må du sannsynligvis gå saktere fram.
Når du har noe som funker, tar du deg tiden til å se på hvordan koden henger sammen? Burde koden henge sammen på den måten? Den koden du skriver blir liggende i kodebasen! Når du nettopp har skrevet koden, kjenner du best hvordan den fungerer. Senere blir det vanskeligere å splitte opp.
—Teodor
LUKE-16: Delt forståelse av hva som er bra
Godt samarbeid krever at vi har en felles forståelse av hva som er bra. Det er ikke nok å ha et mål vi skal oppnå—vi må vi må vite hva som skiller en god løsning fra en dårlig løsning. God kode, godt design, god produktledelse. Når den delte forståelsen av hva som er bra er på plass, blir samarbeid bedre. Når jeg forstår hva Neno og Bendik jobber for å oppnå for å få et design godt, vet jeg hvordan jeg kan bidra som teknolog.
Er det én leder, eller mange som tar initiativ?

.jpg){kind=link}
Soldater i hæren til Romerriket ble ikke bedt om å tenke selv. De fikk trening i å bidra i formasjonen som var bestemt, og straff om de gjorde noe annet.
En gruppe soldater med spyd og høye skjold i en tett formasjon var vanskelig å trenge gjennom.
Disiplin og kontroll er ikke lenger nok for å vinne i strid. David S. Alberts har ledet flere NATO-forskningsgrupper i arbeidet om hvordan militærorganisasjoner bør struktureres, og skriver i Power to the Edge på side 5:
Power to the edge is about changing the way individuals, organizations, and systems relate to one another and work. Power to the edge involves the empowerment of individuals at the edge of an organization (where the organization interacts with its operating environment to have an impact or effect on that environment) or, in the case of systems, edge devices. Empowerment involves expanding access to information and the elimination of unnecessary constraints. For example, empowerment involves providing access to available information and expertise and the elimination of procedural constraints previously needed to deconflict elements of the force in the absence of quality information.
Moving power to the edge implies adoption of an edge organization, with greatly enhanced peer-to-peer interactions. Edge organizations also move senior personnel into roles that place them at the edge. They often reduce the need for middle managers whose role is to manage constraints and control measures. Command and control become unbundled. Commanders become responsible for creating initial conditions that make success more likely and exercise control by:
Creating congruent command intent across the enterprise;
Allocating resources dynamically; and
Establishing rules of engagement and other control mechanisms that the fighting forces implement themselves.
Sammenliknet med militæret går utviklingen i IT fort. Vi trenger at beslutninger kan tas nær problemene vi løser.
Delt forståelse av hva som er bra—når mange tar initiativ
Men hva skal vi gjøre? Når vi sitter på kanten, og har problemet? Skal vi peise på med magefølelsen vår? Hvis alle gjør sin egen greie, har vi ikke én plan. Da er vi ikke ett team.
Finnes det et alternativ?
Ja.
Alle på teamet bidrar med kompetanse på sin ekspertise. Innen hvert fag er det forskjell på det som er bra, og det som er dårlig.
Du er ansvarlig for å bygge delt forståelse av hva som er bra, innenfor din ekspertise.
Som utvikler, designer eller produktleder er du på teamet du er på av en grunn: ekspertisen din er ønsket. De som har andre jobber kjenner ikke faget ditt. Det er derfor vi jobber kryssfunksjonelt. Innenfor samme fag er det heller ikke åpenbart hva den beste løsningen er. Ett design er klart og rent, uten distraksjoner. Et annet forklarer tydeligere til brukeren hvordan produktet skal brukes første gang.
Hvordan bygge fagmiljø når folk er utleid i oppdrag?
I oppdrag er det nok å gjøre. Får du lært noe av andre i Iterate da, eller ser du bare menneskene i teamet ditt? Får du bidratt til fagmiljøet i Iterate, eller melder du deg ut?
Vi har ofte mye å gjøre når vi er i oppdrag. Får vi tid til å bygge fagmiljø i tillegg?
Et godt fagmiljø har mange aspekter. Ett aspekt er delt forståelse av hva som er bra. Sindre og jeg har både likheter og forskjelliger i hvordan vi liker å skrive kode—men vi har en forståelse av hva den andre synes er bra. Vi trenger ikke bli 100 % enige, og gjensidig forståelse er uansett et godt steg mot enighet. Delt forståelse av hva som er bra.
Mange som koder har lært teori om koding i løpet av utdannelsen. I praksis må vi ta valg teorien ikke svarer på.
Mikrobloggeriet er et verktøy for å dele hva du synes er bra, uten styr!
Når du kjører mblog create, får du åpnet en fil med fire
spørsmål:
- Hva gjør du akkurat nå?
- Finner du kvalitet i det?
- Hvorfor / hvorfor ikke?
- Call to action—hva ønsker du kommentarer på fra de som leser?
De spørsmålene er laget for å grave fram hva du synes er bra med det du jobber med nå. Du får reflektert over om du er fornøyd med det du gjør, og du får åpnet for diskusjon.
Tusen takk til dere som har delt på Mikrobloggeriet i desember.
Håvard, Julian, Finn, Sindre, Thusan, Kjersti, Rasmus, Pernille, Richard, Camilla, Ole Jacob, Lars, Ella, Rune og Anders: tusen takk for at dere har skrevet om noe dere bryr dere om under advent i 2023! Det er første steg for at andre kan forestå hva dere synes er bra.
—Teodor
LUKE-15 - Den vanskeligste praten med investorer
Investorjakt og kapitalinnhenting er bortebane for de fleste gründere. I dialogen med investorer er vi derfor ofte mest komfortable når vi snakker om hvem vi er, hvilket produkt og selskap vi bygger, og hva vi har oppnådd frem til nå.
Dette er relevant og viktig, men det er ofte ikke det investorer bryr seg mest om. Jeg har derfor lyst til å dele noen raske erfaringer om hva investorer bryr seg mest om og hvordan vi best snakker om disse temaene.
Investorer bryr seg selvfølgelig om hvem vi er, hva vi bygger og hva vi har fått til. Det er en essensiell del av historien som vi må fortelle for å få dem interessert. Men vi øker sjansen betraktelig for å gå fra en hyggelig prat til seriøs dialog og investering hvis vi tar med to ting til:
- Hvor vi skal
- Hva eierne i selskapet kan forvente seg
1. Hvor vi skal
Kortversjon: Si det med tall (ja, det rimer :)
Investorer går sjelden inn med en investering med mindre de forstår hva pengene de investerer skal brukes til. Får å forklare dem dette, må vi fortelle om hvor vi mener selskapet skal gå herfra. Her er det fint å snakke om langsiktig visjon, og så gjør det mer konkret gjennom å snakke de neste 1-3 årene. Her er det mest effektivt å bruke tall til å kommunisere hva vi tror fremtiden skal bringe: Hvor mye omsetning, hvor stor vekst, hvor mye overskudd og så videre.
Slike tall, som vi ofte kaller projeksjoner er noe mange innovatører ikke er så komfortable med. Jeg tror det har å gjøre med at vi liker å være datadrevet, og at tall om fremtiden føles spekulativt og generelt vanskelig å si noe om.
Det man må huske her er at dette vet også investorene. Iallefall de gode investorene. De har kanskje stått der selv en gang og følt på det samme. Men de vil allikevel se noen tall om hva vi tror vi kan få til. Uten et slikt siktepunkt oppfatter de ofte investings-caset som for vagt til at vi får vippet dem over til å faktiske investere.
2. Hva eierne i selskapet kan forvente seg
Kortversjon: Si når du tror investorene får tilbake mer penger enn de puttet inn
Investorer vil gjerne også høre noe om hvordan de får pengene sine tilbake, og da aller helst mye mer penger enn det de opprinnelig investerte. Nok en gang blir dette spekulasjon om fremtiden, og nok en gang vet også inverstorene at det er spekulasjon. Men de ønsker her også se at vi har noen tanker om hvordan dagen “alle” får betalt vil arte seg.
Dette kan være salg av selskapet, mulighet for del-salg av aksjeposter eller utbytte. Det man sier her bør være beregnet utifra tallene man kom med under punkt 1), hvor vi skal.
Denne delen av pitchen omtales ofte som “equity story”.
Oppsummering
Min erfaring nå etter å ha jobbet utenfor komfortsonen med fundraising i flere omganger, er at jo mer jeg “eier” disse to punktene, desto mer overbevisende blir jeg i investordialogene. Dette blir fort til en positiv feedback-loop, hvor også investorene blir mer gira og det igjen gir meg bedre selvtillit, som igjen gjør at jeg pitcher enda bedre til den neste investoren, som igjen gjør at jeg kommer i dialog med enda flere investorer, og så videre.
Som gründer eller innovatør kan det være vanskelig å knekke denne delen av pitchen alene, og derfor kan det være lurt å få hjelp til å forme disse to punktene, gjerne av noen som har gjort det før. Men klarer man det så kommer man til et mye bedre sted, og man får bedre fremdrift.
Og plutselig går det fra å være utenfor komfortsonen til å bli innafor (og tilogmed litt gøy :)
Java 21 pattern matching
Pattern matching i Java har blitt bra!
JEP 441: Pattern Matching for switch
For eksempel, la oss lage en ny Optional-type av records
og sealed interface:
sealed interface Maybe<T> {}
record Some<T>(T val) implements Maybe<T> {}
record None() implements Maybe {}(En record er bare en enkel data-klasse som ikke kan
utvides eller muteres. På grunn av sealed vet kompilatoren
nå at Maybe kun kan bestå av Some og
None.)
Det stilige nå er at vi kan gjøre switch som sikrer
håndtering av alle mulige tilfeller:
String fun(Maybe<Integer> n) {
return switch (n) {
case None ignore -> "nothing";
case Some(var i) -> String.format("%d.0", i);
}; // ^begge trengs for å få kompilert!
}Det er mulig å nøste og kombinere, la oss lage en til type:
public sealed interface Contact {
record Email(String mail) implements Contact{}
record Phone(int prefix, int number) implements Contact{}
}Og vi kan matche slik:
void handle(Maybe<Contact> c) {
switch (c) {
case None none -> {}
case Some(Contact.Email e) -> sendEmail(e.mail);
case Some(Contact.Phone p) -> phone(p.number);
}
}Om vi ønsker kan vi matche Phone(int pre, int num) i
stedet for Phone p også :)
(P.S. Hvis de ulike typene ikke ligger samme sted som
sealed-interface-et/klassen trengs permits:
sealed interface Contact permits Email, Phone {)
—Richard Tingstad
Pålydende
Kontekst er antall aksjer i et selskap og aksjekapital ved oppstart av nytt selskap.
Dett må ikke forveksles med selskapsverdi, som ofte brukes ved kapitalutvidelse (også kalt emisjon).
Si at et selskap opprettes:
Da kan man selv velge antall aksjer i selskapet. Det er ganske normalt å velge 30 000 aksjer. Siden det er et krav om at selskapet må ha en aksjekapital på minimum NOK 30 000,- ved oppstart, så blir da pålydende NOK 1,- per aksje.
Man kan også velge å ha 100 000 aksjer og sette inn en aksjekapital på NOK 100 000,-. Da blir pålydende også NOK 1,- per aksje.
Man kan velge å ha 100 000 aksjer og sette inn NOK 50 000,-. Da blir pålydende NOK 0,5 per aksje.
—Rune
LUKE-13
Hej och välkomna till Ellas julekalender-inlägg!
När jag bestämde mig för att bidra till julekalenderen och skriva ett blogginlägg så visste jag inte riktigt vad jag skulle skriva om, men jag hade flera idéer. Olika saker jag läst om och tänkt på den senaste veckan, som jag tänkte kunde vara intressant att dela med mig av. Jag tänkte först att jag kanske skulle skriva något om denna artikeln som jag läste nyligen och tyckte var intressant. Den handlar om att gamla filosofer och ny forskning är eniga om att chansen att vara lycklig är mindre för de som uppfattar komplexitet, alltså har mer kunskap eller större intellekt (kanske är det därför så många har sina lyckligaste minnen från barndomen!).
Jag funderade också på att skriva om det som hände på COP28 och direkt efter. Kortfattat så enades alla FN-länder om att världen ska “röra sig bort från fossila bränslen” (det är fösta gången på nästan 30 år som dom har nämnt orsaken till klimatkrisen i avtalet vars syfte är att begränsa just klimatkrisen. Låt det sjunka in). Men bara dagen efter klimatoppmötet säger Norges olje-och energiminister att klimatavtalet “endrer ingenting for Norge” och Offshore Norge delade nya tal som visar att dom förväntar sig 9% ökning av investeringar i olja och gas nästa år.
Men jag ska inte mala på mer om detta. Ni kan googla, fråga mig eller läsa mer här. I helgen hände nämligen något som fick mig att ändra mig. Något som fick mig att bestämma mig. Det är dags för mig att prata om något som jag länge velat prata om, men inte riktigt vågat.
I helgen gjorde Stopp Oljeletinga ett försök att störa världscupen i Trondheim. Det var egentligen inte det som fick mig att bestämma mig. Det jag reagerade på var det som följde. Hoten, hatet. Rubriker i tidningarna och citat som “De skulle hatt juling hele gjengen” och “Hvis de blir hatet, fortsett sånn”. Kommentarsfält fylls av hårda ord. Idioter, tullinger, dere bør skambankes, skulle ha klint alle i bakken med balltre i bahue. Det är ett hat som många av Stopp Oljeletingas aktioner möts av, framförallt de som är riktade mot sportevenemang. Jag har full förståelse för att det är frustrerande när klimataktioner påverkar och kanske till och med förstör för en själv. Det jag inte förstår är hur detta hat och hot mot klimataktivister kan vara så normalt och accepterat i samhället. Hur kan så många vara så arga på dom som tar personliga risker och gör stora uppoffringar för att vi alla ska få en bättre framtid?
Det är nu det blir personligt. Jag gick nämligen själv med i Stopp Oljeletinga tidigare i höst, och har deltagit i flera aktioner. I samband med att jag gick med, gjorde jag några anteckningar som jag vill dela med mig av. I bästa fall kan dom bidra till ökad förståelse, spännande samtal eller nya tankar.
En septemberdag:
Det går upp mer och mer för mig, det jag
trodde att jag redan visste. Hur många som ska dö, som redan dör, av
klimatförändringar. Jag läser en bok skriven av en klimataktivist, som i
många år jobbat inom olika organisationer för politisk förändring. Han
talar klarspråk om klimatförändringarna och vad de innebär, hur det är
att leva under denna tiden, att jobba med att försöka skapa en bättre
framtid trots konstanta motgångar. Om hopp och tvivel, folk som sliter
för att skapa en bättre framtid, men också om dom som jobbar i motsatt
riktning, kanske inte bara för att dom är dumma och tänker kortsiktigt
men också för att dom som är rika nog kanske kan få fördelar av
klimatförändringarna. Jag funderar på att gå med i Stopp Oljeletinga och
hör deras budskap. Jag läser en bok som utspelar sig på landsbygden i
Sverige sent 1800-tal, där dom lever på så extremt lite och svälter i
torkans år. Tänker på hur otroligt långt borta det känns, men hur
nyligen det ändå var det vanliga. Så läser jag Magda Gads rapportering
från Afrikas horn, om flera års torka till följd av
klimatförändringarna, och inser att det pågår svält värre en den i min
bok, just nu, i den del av världen som drabbas hårdast av
klimatförändringarna men har bidragit minst till att orsaka dom. Där dör
två personer varje minut.
Ju mer jag läser, desto mer förminskande,
nästan löjligt, känns det att prata om smältande glaciärer och
snöfattiga vintrar. Visst är det en annan sida av samma mynt - kan vi
stoppa smältandet så förbättras också torkan - men det här handlar inte
om vackra vyer eller skidåkning. Det handlar om död, eller kanske
liv.
En regning oktoberkväll:
Jag var på ett öppet möte med Stopp
Oljeletinga, tre saker minns jag bäst. Det första är det öppna, ärliga,
allvarliga uttrycket hos personerna som var där. Det andra är begreppet
“soft denial” - ett tillstånd som de flesta är i, där vi inte riktigt
låtsas om vidden av klimatförändringarna, för om vi gjorde det, hur
skulle vi då kunna göra annat än att stå på barrikaderna? Det tredje är
hur dom pratade. Han pratade monotont, sluddrigt, med en låg röst, trött
på att behöva gå igenom all denna faktan en gång till. Hon pratade med
gråt i halsen, vädjan, hon slåss ju för hennes liv, och för andras. Och
jag blev övertygad. Inte om att det kommer funka, just metoden civil
olydnad, men att vi måste försöka. Göra allt vi kan, testa alla metoder.
De har bara ett krav, det är ett otroligt lågt mål, det verkar omöjligt
att inte hålla med om. Att inte dela ut nya licenser för
oljeletning.
Men jag tvekar ändå, för jag är rädd. Rädd för något mer omedelbart än klimatförändringarna. Rädd på ett mer själviskt plan. Jag är rädd för konsekvenserna, tvekar för att jag inte är beredd att ta dom. Konsekvenserna av civil olydnad. Jag är rädd för straffen. Jag vill inte betala böter, hamna i häkte eller fängelse, inte ens bli bortburen av poliser. Och jag är rädd för vad folk kommer tycka, tänka, säga. Hoten, hatet. Sug min kuk, jävla puckon, ni borde avrättas, sånt som sägs efter lite färgpulver i målgången på en tävling i rullskidåkning. Dom bara förstör, dom gör folk arga, så jävla dumma. Orden jag hört närstående säga om tidigare aktioner, soppan på (glasrutan framför) Skriet. Om jag går med, så kanske jag inte berättar det för så många.
Men ännu mer rädd är jag för konsekvenserna av klimatförändringarna. Det är väl därför som jag måste göra detta.
Sedan jag gjorde dessa anteckningar har jag själv fått uppleva hoten och hatet. Och jag har hört aktivisterna prata, innan och efter aktionerna. Jag har upplevt deras omtanke och mod, jag har sett dom rädda, ledsna, och beslutsamma. Jag har varit en av dom, planerat aktioner, delat min oro, sett den i deras ögon med. Jag vet att ingen av dom deltar i aktioner för att dom tycker det är kul, ingen gör det med lätthet.
Varför vi, trots all ilska, använder oss av metoden med icke-våldsam
civil olydnad kan vi prata mer om nästa gång. Idag vill jag att vi
fokuserar på hatet. Varför riktas allt detta hat mot oss? Är ilskan mot
oss rimlig? Eller hör den egentligen hemma någon annan stans?
Vi
menar att kritiken hellre bör riktas mot det verkliga problemet –
utvecklingen av olje- och gasindustrin mitt i klimatkrisen.
P.S. Det är viktigt att veta att Stopp Oljeletingas aktioner är “non-violent”. Det betyder att dom är fredliga, att det är viktigt att inte orsaka skada. Vi ska vara passiva och inte ens försvara oss om vi blir attackerade.

LUKE-12 - Anbefalinger fra 2023
Jeg velger å bruke luken min på å skrive en slags oppsummering og anbefalinger fra ting jeg har likt i 2023. Ganske så fritt etter hva jeg kommer på en mandags ettermiddag.
Jeg koste meg veldig med Lincoln Highway av Amor Towles i sommer, så mye at jeg endte opp med å også lese de på andre bøkene han har gitt ut. Den handler om to brødre som flykter fra fortiden sin i midtvesten og setter kursen mot California, men blir raskt innhentet av den og må sette kursen mot New York i stedet.
Jeg fortsetter med å anbefale ting som er et par år gamle, Susanna og David Wallumrød laget et veldig flott live-album i 2021, Live. Rolig og stemningsfullt.
Ferskere og mer fart får du med Andre Rolighetens Marbles.
Det er kanskje litt rart å kåre den til årets beste TV-serie, når bare halvparten rekker å komme ut i 2023, men det er utrolig gøy at Fargo endelig er tilbake (i Norge finner du den på HBO Max). Det er en antologiserie, det vil si at hver sesong er sin egen lille historie med nye karakterer, så selv på sesong 5 er den et friskt pust. Det de har til felles er at de alle er i Minnesota-området og tar med seg noe av stilen, og brutaliteten, til spillefilmen. Som jeg leste et sted, sesong 5 er en god blanding av “Hjemme Alene” og “True Detective”.
Til slutt en faglig anbefaling, Kent Beck har gitt ut en ny bok Tidy First? Her er spørsmålstegnet viktig, når skal man ryddige i koden? Når det er avklart, du må gjøre det som lønner seg mest, kommer det en rekke tips til hvordan rydde. Les mer på substacken hans.
OLORM-46: kortsiktig og langsiktig arbeid med kode
I prosjektet jeg jobber på nå, skal jeg inn, gjøre en jobb, og ut igjen innenfor planlagt tid. Det er mye kode, og jeg har ikke tid til å lære meg alt. I tillegg har kunde hatt høye krav til hva som må inn, og begrenset budsjett.
Jeg føler på kroppen at jeg ikke er i stand til å gjøre de beste beslutningene om hvordan en ting bør løses i kodebasen. Jeg har tid til å sette meg delvis inn i eksisterende arkitektur og hvordan det har blitt jobbet, men for å faktisk komme i mål med det jeg skal gjøre må jeg sette strek. Det er det pragmatiske valget; kunden har et behov, jeg kommer og gjør en jobb, og skal gjøre den jobben til budsjettert tid. Kodeteknisk vet jeg at det er ting jeg bør ta tak i som jeg ganske enkelt ikke rekker.
Jeg er overbevist om at kode kan være objektivt god.
- Fiks en flaky test? Objektivt god forbedring.
- Sørg for at testene kjører i CI? Objektivt god forbedring.
- Redusér tiden det tar å kjøre testene fra 10 sekunder til 0.2 sekunder? Objektivt god forbedring.
Denne typen forbedringer får jeg sjelden tid hvis jeg er “inn og ut” på et prosjekt.
Å bli en god utvikler krever langsiktighet nok til at man rekker å sette seg inn i ting, bli produktiv til å jobbe med koden, så oppleve effekten av arkitekturen på egen effektivitet, så oppleve effekten av forbedret arkitektur.
Akkurat sånn har jeg lært å programmere. Jeg har satt opp et prosjekt. Prosjektet har etter hvert løst problemet det skal løse. Så har jeg merket at enkelte biter av arkitekturen lugger. Så har jeg endret arkitekturen, og fikset problemet.
Bør man lære seg å jobbe med produkter og lære seg å jobbe med kode samtidig? Jeg mener nei. Uten god kode er det null sjanse for at vi klarer å lage gode produkter. Men med svært solid kompetanse på kode, er det mye lettere å lage gode produkter. Kan du gjøre en solid forbedring på koden på én dag? Bra. Er du ikke der ennå? Da kan ting forbedres! Du kan forbedres, koden din kan forbedres.
Og når forbedringer på produktet kan shippes på én dag i stedet for på to uker, kan jeg love deg at jobben med å lage et godt produkt blir lettere.
Kjersti skriver om å avfeie kundens meninger i LUKE-6 - Kunden tar alltid feil!:
Kanskje vi ville bli bedre på å ta utgangspunkt i kundens hypoteser dersom vi samlet sett vet at vi ikke blir «tatt» på å feile litt lenger ned i løypa (ref punkt 1). Her har jeg egentlig et veldig stort spørsmål: hvordan balanserer vi vårt eget behov for å forstå med kundens forståelse av markedet vi skal inn i? Jeg har en følelse av at vi blander kortene her.
Hvis vi ikke tar kundens hypoteser seriøst, bør ikke kunden leie oss inn.
Grav i hva hypotesen er. Vær ekstremt nøye på de spørsmålene. Men ikke påstå at det er feil! Ikke før du har prøvd.
Tidpunktet å diskutere hypotesene er etter en hypotesetest, ikke før. Snakk om hva den første effekten vil være hvis det vi gjør går bra. Det er hva du vil teste. Snakk om hvilken tidshorisont kunden ser for seg å få til det på. Flott, da vet du cirka hvor stor denne klumpen med arbeid er.
Så kan du se nøye om det faktisk fungerte ikke når du har prøvd på ekte.
Er dette mye å forvente? Ja! Bli gjerne god på å kode først. Men ikke avfei det kunden sier før dere har prøvd: følg Principle of charity før du setter deg selv i kritikkmodus. Bonus: når du viser villighet til å prøve, begynner kunden å stole på deg. Når kunden stoler på deg, er det mer sannsynlig at du blir hørt.
—Teodor
LUKE-11 - For forbrukere
Vær en god forbruker!
En ting jeg har irritert meg over helt siden jeg måtte kjøpe mine
egne ting her i livet, er planlagt foreldelse (kanskje
kjent bedre som “planned obsolence”). Jeg irriterer meg også over
produkter med dårlig kvalitet. Det verste er kombinasjonen av disse.
Fight me, big corp!
jk
Hva?
La oss ta et eksempel:
McDonalds, Coca Cola og Capri
Sonne.
Dette er alle eksempler på produkter som skal smake likt i
hele verden. Forrige setning er en løgn, i Europa er det stort sett
sukrose som brukes som søtningsmiddel, kontra glukose-fruktose sirup
(HFK) rundt om i verden. Uansett, de gangene jeg kjøpte meg Coca-Cola
etter fotballtrening i Kåffa-hallen, så hadde jeg en
forventning om hva det skulle smake. Var jeg heldig, så smakte den
litt feil.
Hvorfor var jeg heldig om det smakte feil?
Jo, for da kunne jeg
ta bilde av produksjonsstemplingen, sende en mail til kundeservice, og
få hele TO poletter jeg kunne bruke på ny brus. Jeg har seiret over big
corp! Det samme gjør jeg dersom cheeseburgeren smaker feil, mangler
sylteagurk eller bare ikke står til forventningene.
Som 15-åring hendte det jeg tøyde strikken litt, og begynte å klage
på at et av speileggene i min nyinnkjøpte Haribo Stjernemix manglet
eggeplomme, riktignok funket det fint hos Brynhild da bringebærdropsene
var smeltet sammen.
Eller da Ballerina-kjeksen manglet det digge i
midten.
Eller da Troikaen hadde sukkerblomstring på seg.
Leser du fortsatt?
Nå er det jo juletider, og hva passer ikke
bedre enn en historie om julegaven min som er godt over 10 år gammel,
riktignok ikke i samme form eller farge lenger, men gaven lever
fortsatt! Jeg fikk meg et nytt par hodetelefoner. De fungerte veldig
bra, men etter å ha blitt most ned i en sekk hver uke, så begynte
ulempene med plast å vise seg.
Ting knakk, gaffaen var for svak.
Jeg ville ikke bruke penger på nye hodetelefoner!
15 år gammel
skrev jeg følgende:
My question is that if i’m getting another * modellnavn * because my current one is having huge difficulities.
When I was listening to some music yesterday suddenly it came a very high pitched noise for about thirty seconds, then I turned it off, and the same thing appeared. I replugget it and now its blinking green while it’s turning off and on..
Please help me solve this.
Som svar fikk jeg:
Thank you for contacting * firma *’s Customer Care.
I discuss the issue with my supervisor and we are happy to fulfill your replacement without pick-up procedure.
Nice, jeg fikk både beholde mitt gamle, og få et nytt!
Jeg talte akkurat 59 e-postkorrespondanser mellom meg og dette firmaet. Det har resultert i 3 nye datamuser, 5(?) hodetelefoner, hvor jeg alltid har fått toppmodellen tilbake (de sluttet å produsere den jeg fikk i gave for 7 år siden).
Hva har jeg lært av dette?
- Spør du, så får du.
- Vær bevisst på rettighetene dine som forbruker.
- Er kundeservice vanskelig, vær vanskelig tilbake. Du kan for
eksempel si at du skal bleste svaret dems til alle du kjenner, aldri
handle på butikken igjen (det fikk Kiwi til å slette parkeringsboten
min), eller at du blir veldig skuffet over merkevaren, som du har
støttet i alle år.
- Forvent kvalitet.
- Kjøp kvalitet.
- Kontakt produsent først, butikken sender deg som regel dit.
- Det kan godt være din egen feil, Norrønna sendte meg en ny glidelås etter jeg rev i stykker den opprinnelige.
- Tenk cost per use, høy pris betyr ikke nødvendigvis dyrt.
- Vedlikehold er lurt.
Hvis man som forbruker er flink på dette, så blir produsentene forhåpentligvis flinkere til å produsere ting som varer.
Mine topp “Buy it for life” ting/merkevarer:
- Kitchen Aid i metall fra 70-tallet
- Ordentlige lærsko med Goodyear-welt eller tilsvarende
- Swiss Army multitool
- Voksede jakker
- Klær uten spandex
- Elektriske ting uten smart-drit, jo mer kretskort, jo fler ting feiler
Apropos elektriske ting som feiler, jeg lærte forleden dag om eFuse, en slags programmerbar sikring.
AMD says overclocking blows a hidden fuse on Ryzen Threadripper 7000 to show if you’ve overclocked the chip, but it doesn’t automatically void your CPU’s warranty tomshardware
Flott for bruktmarkedet, da slipper man å kjøpe et grafikkort som har minet bitcoins hele livet. Samsung derimot, bruker det for å bricke mobilen din dersom du prøver å tukle med den. Det er litt som fukt-indikatorene som alltid fjerner garantien din..
Thank you for considering my complaint, Ole Jacob
LUKE-10 - En rar ting som skjedde forrige uke
Da jeg først sa jeg kunne skrive noe til denne julekalenderen, tenkte jeg å skrive noe om tegneserieromanen jeg har laget de siste to årene. Samtidig så kjenner jeg på at jeg ALLTID snakker om tegneserien, og burde ha noe annet å komme med også. Men, har jeg egentlig noe annet å skrive om? Nesten hele livet mitt dreier seg jo om tegneserien for tiden.
Så kom jeg på: Heldigvis har det nettopp skjedd noe veldig rart med meg - og det har ingenting med tegneserien å gjøre! Hva i all verden? Jo, nå skal du få høre: Noen av dere følger kanskje @badesken på sosiale medier, og har fått med seg dette lille innlegget han skrev for noen dager siden. Haha, så morsomt! Det er jo helt sprøtt at en full fyr begynner å måke verandaen til en fremmed midt på natten. Joda. Men det som hverken stod i det innlegget, eller i Adresseavisens lille artikkel om hendelsen, er at han også kom seg inn i leiligheten til naboen til dem han hadde måket snø hos. Og hvem bor i den leiligheten? Jo det er meg, samboeren min Alexander, og katten vår Ellie.
Vi har en leilighet i første etasje, i et stille område på Tyholt. Man kan gå fra balkongen og rett ut i den fine skjermede hagen, og vi slipper derfor Ellie ut og inn av balkongdøren hele dagen lang. Og ofte så gidder vi ikke å låse den, selv når vi er borte en tur på dagen - eller når vi sover. For katten skal jo ut og inn støtt og stadig, og det skjer aldri noe på Tyholt.
Men natt til lørdag så skjedde det faktisk noe. Jeg våknet av lyden av en stemme, og føtter som gikk i stua. Jeg skjønte ingenting. Men jeg ble ikke redd, av en eller annen grunn. Jeg tror jeg tenkte det kanskje var sønnen til naboen, som gikk inn i feil leilighet ved et uhell. Jeg dyttet borti Alexander, så han også våknet. Og så bare kom det en fremmed fyr inn på soverommet vårt, og lyste på oss med lys fra mobiltelefonen sin. Han sa hei, og virket veldig blid og glad og bablet i vei på en litt usammenhengende måte. Vi skjønte ingenting. Så ville han ha en fist bump fra oss. Han fikk det, for hva gjør man ellers når man ikke er helt våken og en fyr vil ha en fist bump midt på natta? Og han sa noe om at han måtte gå og hilse på noen sin svigermor? Verden hadde fullstendig sluttet å gi mening.
Det neste som skjedde var at han sa pent ha det bra til oss, og gikk ut av soverommet og lukket døra. Og så låste han døra etter seg, for nøkkelen sto av en eller annen grunn i på utsiden av soveromsdøra. Og det var jo litt creepy å bli låst inne på eget soverom. Vi rakk å tenke på om vi måtte klatre ut av soveromsvinduet for å komme oss ut. Men Alexander banket litt på døra og ba han om å låse opp - og da gjorde han det, og sa unnskyld. Jeg tror ikke han låste oss inne med vilje. Men det ble bare tydeligere og tydeligere at han ikke hadde helt kontroll på virkeligheten for øyeblikket. Han klarte ikke å forklare hvem han var eller hva han skulle, og luktet sterkt av sprit. Men han var fremdeles blid, og på ingen måte truende. Han begynte å ta av seg jakka, som om han bare skulle slå seg ned littegranne. Alexander, som fremdeles bare hadde på seg underbukse stakkars, prøvde å fortelle ham at han måtte gå nå - men det virket ikke som om han forsto helt hvorfor han skulle det.
Så ringte naboen meg - hun sa hun hadde ringt politiet etter at han hadde prøvd å komme seg inn hos dem, og politiet var der nå. Hun nevnte ikke det med at han hadde måket verandaen hennes, men jeg vet hun ikke synes det var så morsomt eller hjelpsomt som det ser ut som på instagram. Det tok ikke lang tid etter hun la på, før politiet kom traskende rundt huset og opp på balkongen vår.
Politiet kom inn den ulåste balkongdøra, fikk mannen til å kle på seg jakka igjen, sjekket lommene hans for at han ikke hadde tatt noe, og tok ham med seg ut og vekk. Det var over like brått som det startet. Og vi sto igjen i en slags mild form for sjokk, en følelse av å ha hatt en rar drøm.
Så, det gikk helt fint! Ingen og ingenting ble skadet eller stjålet. Ingen ble livredde en gang - for vi var for forvirrede til å bli skikkelig redde. Den eneste konsekvensen var at vi slet med å sove resten av natta. Selv Ellie slet med å roe seg ned, men til slutt la hun seg i armkroken min og purret høyt i noen timer helt til vi alle sovnet. Dagen etterpå fant vi lua hans i stua. Den gikk i søpla.
Hele denne hendelsen er litt ukomfortabel å snakke om - og ikke bare fordi det var creepy å ha en fremmed på besøk midt på natta. Men også fordi jeg føler meg flau over at balkongdøren var ulåst. Det var på en måte vår egen feil at det skjedde - og samtidig var det jo ikke det. Men jeg kjenner litt på skammen, og er litt nervøs når jeg tenker på hendelsen. Selv om det også på et vis er ganske morsomt.
Jeg lurer på hva mannen følte dagen derpå. Husker han noe av det? Vi har fått vite litt om ham i ettertid, og han virker som en helt normal fyr på 22 år. Jeg ser for meg at han er skikkelig flau og ukomfortabel når han tenker på det, han også.
Vi sover heldigvis godt igjen nå, og ikke bekymre dere - vi skal huske å låse balkongdøra fra nå av!
LUKE-9
I en tid før grafiske brukergrensesnitt pleide IT-folk å sende slike julehilsener til hverandre:
◆ ◆
⎽⎽⎽⎽⎽⎽⎽⎽┌┐⎽⎽ / \
↓ / └┘ \ / → \
┬────────────┬ / ° °\
────────────┤ ┼┼ ┌──┐ ┼┼ ├─────────────/ ↓~ ° \
│ │-.│ │ /⎽⎼─┬─┬─⎼⎽\
└────┴──┴────┘ ┌─┴─┴─┐
└─────┘Denne kommer fra et arkiv av “VT100-animasjoner”, mange stammer fra 1980-tallet.
Disse er jo hyggelige og fine, men… 🤔 ASCII-standarden fra 1963+
inneholder bare 128 symboler og ┐, ┴ og
◆ er ikke blant dem — Unicode og UTF ble jo ikke oppfunnet
før på 1990-tallet! Jeg leste filene direkte, så hvordan virker dette
egentlig?
VT100 er en dataterminal som ble utgitt i 1978 (fysisk maskin, produsert av Digital Equipment Corporation, DEC) og manualen sier:
The VT100 has many control commands which cause it to take action other than displaying a character on the screen. In this way, the host can command the terminal to move the cursor, change modes, ring the bell, etc. […]
| Character set | G0 designator |
|---|---|
| United States (USASCII) | ESC ( B |
| Special graphics characters and line drawing set | ESC ( 0 |
Så hvis terminalen mottar tegnene ESC (
0 bytter den tegnsett til Special graphics and line
drawing.
Mange av disse kontrollkodene er standardisert i ANSI X3.64 og
X3.41/ECMA-35(1980),
men hvilke tegnsett (B, 0) som
implementeres er ikke spesifisert.
Uansett kan vi lese i Linux-dokumentasjonen om Console Controls:
| ESC ( | Start sequence defining G0 character set (followed by one of B, 0, U, K, as below) |
| ESC ( B | Select default (ISO 8859-1 mapping). |
| ESC ( 0 | Select VT100 graphics mapping. |
Jeg liker at plattformer har bakoverkompatibilitet, og dette er et heftig eksempel. Jeg kan her nyte, rett ut av boksen, innhold og kontrollkoder produsert for 40 år siden, på min moderne Mac eller Linux-maskin.
La oss i denne adventstiden sette pris på all kode og innhold skapt i 2023 og tidligere, som fortsatt virker som det skal 🌟
Min gave til dere i denne kalenderluken er julehilsen fra fortiden:
printf '\033[?25l' # skjul markør
curl -s http://artscene.textfiles.com/vt100/xmas2.vt \
| node -e 'require("fs").readFileSync(0).forEach((b,i)=>
setTimeout(()=>process.stdout.write(Buffer.from([b]).toString()),i))'—Richard Tingstad
LUKE-8 - Et juleevangelie om håndarbeid
Nesten alt jeg gjør på jobb foregår digitalt. Jeg jobber digitalt, hobbyene mine er digitale, resultatene kan bare sees digitalt, og når jeg reiser meg opp og går blir det jeg har gjort igjen. Det fikk meg til å ville plukke opp en hobby som resulterte i noe håndfast som jeg både kunne se fysisk mens jeg jobbet med det, og ikke minst se resultatene av etterpå. Noe jeg kan holde opp og si “Se! Dette laget jeg”.
Dermed vil jeg gjerne slå et slag, et lite juleevangelie om dere vil, for konseptet håndarbeid.
Søm og strikk er to måter å skape et klesplass på som kan virke ganske like. I alle fall trodde jeg det da jeg tok dem begge opp som covid-hobbyer. Jeg er tross alt, i likhet med mange andre her skulle jeg tippe, glad i og ganske flink til å følge algoritmer og/eller oppskrifter og gjøre ting nøye.
Når du syr, må du først dekonstruere et plagg du ønsker (eller betale noen for å gjøre dette for deg), fra et tredimensjonalt plagg som former seg rundt deg, til en samling todimensjonale flater. Deretter må du finne et materiale som passer i form, størrelse, farge, tekstur, og styrke, klippe det til i formene du trenger, og finne en måte å sette dette sammen igjen. Dette må gjøres på riktig måte og i riktig rekkefølge slik at du til enhver tid sjuler sporene dine. Litt som et puslespill.
Strikking på den andre siden er som 3D-printing, du vever materialet ditt direkte inn i den endelige formen det skal ta. Du finner en oppskrift, regner deg frem til mengde materiale du trenger, sammensetning fiber, og farge, og krysser fingre og tær for at du regnet riktig og ikke må kjøpe mer garn underveis, for å legge til mer underveis kan du bare glemme.
Hvordan?
Selve jobben med søm er raskere, det er en del forberedelser men hvert steg er ikke så langt eller komplisert, så lenge du bruker en symaskin. Det er også bare fantasien og evner (og budsjett) som setter grenser for hva du kan lage. Men, med alle forberedelsene det krever er det så mye setup at du fort vil gjøre alt sammen på én gang. Du havner fort i flytsonen, så da sitter du der til du er ferdig, før du plutselig ser opp. Det er mørkt ute, du har ikke drukket på 6 timer, du har vondt i ryggen og har glemt å spise middag. Men, plagget ble ferdig. Det er ikke en hobby som krever veldig mye tankekraft, men det krever nok konsentrasjon til at det er vanskelig å gjøre noe annet samtidig. Du KAN ha laptopen ved siden av deg med en film på, men du ender nok opp med å enten ignorere den, eller pause den og finne frem oppskriften din i stedet.
Strikk derimot, tar utrolig lang tid. Time opp og time ned med repetative bevegelser, der du saaakte men sikkert konstruerer plagget ditt. Det går kanskje saktere, men det er også den ultimate “gjøre noe med hendene mens du tenker på noe annet” oppgaven. Du kan velge å lage noe med akkurat nok variasjon til å holde deg interessert, men ikke så vanskelig at du må tenke veldig mye. Det er noe å gjøre med hendene mens du ser film, serier, eller føler du bare må fikle med noe. Det er også utrolig lett å gjøre bare litt av gangen, og ikke minst. Du kan gjøre det sittende tilbakelent i sofaen.
Så hva er riktig for deg? Det kommer litt an på. Med søm kan du lage uendelig mye greier, og du lærer mye som er nyttig i forhold til klær du allerede har. Legge opp bukser, ta inn eller legge ut klær som er for store eller for små, legge til lommer på klær som ikke har det men burde. Men det er en “IKKE SNAKK TIL MEG JEG ER OPPTATT” hobby, der du gjør skippertak og er sliten og støl etterpå. Opp i mot strikk, der du sitter på sofaen og sipper kaffe og har noe å holde på med i stedet for å scrolle på telefonen samtidig som du også ser på TV. Det sies også at dette er en måte å holde hendene opptatt mens du sitter i videomøter som ikke er å fikle med en hårstrikk, en kopp, eller brillene sine, men dette ville jeg sett an stemningen på. Så må du også bare huske å aldri gjøre noe feil, for gjør du noe feil i strikk kan du som regel bare glemme å reparere det, du må rekke opp alt du har gjort ned til feilen for å gjøre det på nytt. Og så tar det gjerne et par uker å lage noe, mot et par kvelder med symaskin.
For en ekstra bonus, om du har et lite barn og to katter og/eller er i situasjoner der du plutselig må legge fra deg alt du holder på med og gå, er strikketøy ganske mange ganger lettere å kaste fra seg. Ingen “katt sitter fast i symaskin” redsel.
Uansett, ender du opp med noe håndfast du kan vise frem etterpå og si JEG HAR LAGET DETTE! Og uansett hvor brukbart det ble, så er det en veldig fin følelse når du ellers bare jobber digitalt.
LUKE-7 - Jeg havde en eksistensiell krise på polet i dag:
Hadde av noen rar grund lyst på whiskey - måske fordi jeg er overarbejdet - måske bare fordi det er koldt, mørkt og kedeligt langt inn i den kolde november sjæl.
Det gav sig under alle omstændig til udslag i en uanstændigt tur på polet - denne gang den på Karl Johan - ved siden af nisseland - til lyden af julemusik og lukten af friteret sukkerholdig gjærbaks og skrikende forbruksfikserte ungdom med foreldre med dårlig samvittighed på slæb.
Jeg så en medarbejder i det jeg trådte ind i butikken. Turde ikke møde hans blik - han ignorerte på høflig vis meg med det samme, med kun den overlegenhet som storby Pol-ekspedienter kan
- han kunne jo godt se at jeg er sådan en, som egentligt ikke riktig ved noget som helst om god sprit - at jeg er en af de der som drikker alkoholfri øl i helgene for ikke at ødelægge meget efterstræbet nattesøvn. Med andre ord: En mann med et lettere apatisk blik, men dog med et stødig skridt fandt jeg hurtigt min vej til Whiskey afdelingen.
Her ble det klart for meg, at jeg var ute på dybere vand, end først antaget.
Jeg liker jo egentlig ikke spesielt godt whiskey - eller - jeg liker jo Burbon på et vis. En amerikansk perversion af de finere angelsaksiske traditioner for fad-lagring og tung druk.
Så der sto jeg. Hadde lyst på whiskey, men egentlig Burbon og så heller ikke det, for jeg tenkte ved meg selv: hvem drikker rent Burbon? Så jeg sto å så på Jack Daniels og Kentucky Burbon og følte meg mer og mer fortabt. Sådan holdte jeg på i mellem 5 - 10 minutter før jeg besluttede mig for at en stor flaske Burbon heller ikke slo an.
Flere mennesker kom og gikk rundt meg. Opslugt i deres egne tanker og opgaver. Jeg følte meg Klein som jeg stod der. Fortabt. Uden mål og mening. Det var efterhånden blevet meget varmt at stå i min vinterjakke inde på polet.
Da en mand med overvældende kraftig bållugt gik forbi mig, gik det op for mig - jeg måtte velge meg et nyt dogme for min søgen! Og som En slags messias som skulle lede meg til den trygge stald , bestemte jeg mig for at gå efter den whiskey med mindst røg-smag! OG siden jeg jo egenligt ikke så godt kan lide whiskey: den mindst flaske …
Her slutter historien om mit indkøb af den mindste flaske Dalwhinnie Single Malt som findes på monopolet.
Jeg drak et glas med massere is her til aften og var meget positivt overrasket.
Frelst fra røgen og ind i varmen.

LUKE-6 - Kunden tar alltid feil!
Eller? Har kunden alltid rett?
Det er en vanskelig balansegang. Ofte har vi rett i at de ikke har testet nok med markedet. Men, betyr det at vi alltid skal utfordre kunden på hypotesene sine? At vi alltid skal rykke dem tilbake til start? Når skal vi la tvilen komme kunden til gode, uten at det betyr at vi aksepterer alt uten å verifisere? Jeg har tenkt mer og mer på at vi må starte der kunden er, og ikke la oss styre ned i detaljer de allerede (mener de) kan fordi vi selv har behov for å forstå. Hvordan skal vi ha guts nok til å ta en sjans, basert på kundens kunnskap? Hvordan skal vi bruke målinger for å gjøre en avsjekk av hypotesene i det markedet kunden har valgt seg? Når skal vi utfordre sannhetene, og hvordan gjør vi det på en måte som er genuin, effektiv og styrker relasjonen vår til kunden?
Synliggjøre hvilken risiko som tas
En av grunnene til at jeg messer om et felles språk er økt evne for oss å fortelle hvilken risiko det er å bygge noe før vi har nogenlunde koll på hva som skaper verdi for kunden. Noen ganger er kunden ganske sikker i sin sak og da er vel det enkleste å fortelle dem hva det betyr for oss i et produktutviklingsperspektiv (verdens lengste ord), ved å plassere ideen på s-kurven. S-kurven funker til to supre ting med en kunde:
- Si noe om hvordan et produkt/et selskap utvikler seg (som regel veldig gjenkjennbart)
- Og si noe om hvilken risiko som er størst i hvilken fase og hvordan vi jobber for å kontre dette
Når vi da plasserer ideen deres på forskjellige stadier i s-kurven kan vi så snakke om hvilken konsekvens det har å starte på starten eller å starte med skalering (der de fleste mener å være). Det er sjans det er helt fint å la kunden ta, så lenge de vet at det er det de gjør. Et valg tatt med åpne øyne er mye enklere for dem og oss å navigere i etterkant.
Skille mellom vårt eget behov for å forstå og markedets egentlige interesse (kanskje spesielt i B2B)
Denne er vrien, synes jeg. På mange måter må vi forstå en god del for å designe og bygge smart. Her har vi fordelen av å erfaring som vi kan trekke på, aller helst på tvers av alle i Iterate (her kan vi bli bedre). Men ikke alle har denne fordelen i seg selv eller god nok kontakt med kollegaer til å trekke på deres erfaringer. I tillegg så er vi godt oppdratt til å trekke alle gode ideer i tvil dersom ingen, eller veldig få, har betalt for en tjeneste/produkt enda. Vi er helt avhengige av å forstå verdi gjennom hva kunden gjør, på ekte. Kanskje ville vår usikkerhet bli mindre om vi har bedre læringsarenaer på tvers, og flere måter å hekte oss inn på andres kompetanser i prosjekt. Kanskje vi ville bli bedre på å ta utgangspunkt i kundens hypoteser dersom vi samlet sett vet at vi ikke blir «tatt» på å feile litt lenger ned i løypa (ref punkt 1). Her har jeg egentlig et veldig stort spørsmål: hvordan balanserer vi vårt eget behov for å forstå med kundens forståelse av markedet vi skal inn i? Jeg har en følelse av at vi blander kortene her.
Bruke ekte data som navigator
Uansett hva motivasjonen vår for å utfordre kundens hypoteser er så synes jeg det er superfint å ikke mene så mye om hypotesene, men designe tester som gjør at tall og intervjuer kan vise oss veien videre. Det er på en måte ikke min jobb å mene noe om kundens løsning, de vet etter all sannsynlighet mye mer enn meg. Det min jobb er, vår jobb, å sikre at vi beveger oss stadig nærmere en løsning som kunden til kunden elsker. Det vet vi når kunden, tross mangelfull funksjonalitet og småfeil, likevel velger å bruke det vi lager. Så lenge vi samler ekte data, og bruker den ofte, så kan vi gjerne starte der kunden vår mener verdien ligger. Og justere kursen etter hva tallene indikerer. Da vet vi også når vi skal utfordre, noen ganger trenger vi ikke si det, engang. Alle ser jo at ingen vil ha når tallene kommer på bordet..
Unngå stillingskrig
En liten tilleggstanke. Når vi bruker ekte data aktivt vil vi ofte kunne diskutere veien videre mer effektivt, det er tallene som vi må forstå - vi unngår stillingskrig basert på min og din mening. Det er det ingen av oss som liker, og både vi og kundene våre blir sure. Ingen liker å være sure på jobb. Kanskje ligger løsningen i å ta det kunden sier for gitt, for så å designe gode eksperimenter som gir oss ekte data å justere etter. Da blir det både felleskap, læring og økt sjanse for å skape noe av verdi ♡
LUKE-5 - Om å lære offentlig
Jeg lærer meg Haskell, og har valgt å gjøre det offentlig i kanalen #thusan-lærer-haskell.
Hvorfor?
- Jeg har et ekstremt behov for anerkjennelse.
- …
- …
- …
- Jeg har et ekstremt behov for anerkjennelse.
Det kan være vanskelig å lære seg nye ting. Bøker og ressurser på internettet hjelper. Finne andre å lære sammen med hjelper. Finne noen som kan lære bort, hjelper kanskje enda mer. Så, hvordan finner man disse menneskene i Iterate?
Obvs (forkortelse for obviously, obvs), så fins det mange måter å finne disse på lol (forkortelse for “jeg har aldri vært kul”). Jeg valgte å lage kanal og annonsere at jeg skulle poste om læringsprosessen. Fordi, jeg har et ekstremt behov for anerkjennelse.
Det har (inntil videre) hatt følgende effekter:
- Asynk diskusjoner om noe jeg har tatt opp i posten min. F.eks. denne som kom etter at jeg kommenterte at koden min føltes kanskje litt imperativ.
- Kommentarene er kjempe verdifulle for meg.
- Mange av de som kommenterer på postene mine ser jeg ikke daglig, og det er jo ikke sånn at man nødvendigvis har tid til å loke med Haskell ila. arbeidsdagen.
- Har opplevd at noen tar meg til side når vi møtes fysisk og dropper en eller annen Haskell fun-fact.
- Blir fortalt om Haskell konsepter, uten at jeg har ramlet over det selv. Som f.eks. currying og pointfree
- Loggføring av min innsats. Det har mange naise effekter. Jeg kan lese tankene jeg gjorde meg opp om forrige økt, i tillegg til å se på koden jeg har skrevet. Det er nais, fordi det har hittil gått i snitt litt under 8 dager mellom hver økt. Jeg husker ikke middagen jeg spiste for 8 dager siden.
- Det å skrive ned ting mens jeg jobber med det, gjør at jeg effektivt rubber-ducker med meg selv. Som har ført til at jeg noen ganger løser problemer jeg ikke skjønte svaret på før jeg begynte å skrive ned problemet.
Jeg tror man har lyst til å hjelpe folk som prøver. Kanalen er et bevis på at jeg prøver, og jeg velger å tro at man kanskje blir litt gira av det og hjelper til. Det at folk følger med gjør at jeg føler meg accountable og faktisk skriver ned ting (selvom det ikke alltid er bra).
Oppfordrer flere til å lære offentlig! Det er kult å se hva folk bryner på, og potensielt kunne bidra til det.
Sist men ikke minst, takk til alle som gidder å lese og hjelpe. Det setter jeg utrolig stor pris på.
LUKE-4 - Code Coverage
Jeg digger code coverage.

Code-coverage gir meg mulighet til å se hvilke deler av kodebasen min som har kjørt og ikke har kjørt. Typisk samler man inn code coverage når man kjører tester. Da får man se hvilke linjer med kode som testen har “aktivert” og ikke aktivert.
Se på eksempelet over. Dette er litt Rust-kode fra den virtuelle maskinen i Unicad, men hva den gjør er ikke så viktig. Kode merket med rødt blir aldri kjørt, kode uten farge blir kjørt og i margen kan man se antall ganger koden har blitt kjørt. Kode merket med blått er en “branch” som har kjørt et annet antall ganger enn den linjen den er en del av.
Her kan vi se at mesteparten av koden blir kjørt i testene, med noen få unntak:
- binary_op feiler aldri i en test, så feilmoden der blir ikke aktivert (spørsmålstegnet er rødt)
- self.negate feiler heller aldri i en test
- Ingen tester får en runtime_error med
VARIABLE is undefined
Så hva betyr det? Hva gjør vi med den informasjonen?
Først to ord om hva som ikke er nyttig. Code Coverage kan regnes ut som et tall, hvor mange prosent av koden min er dekket av testene. Og idet man har et tall er det lett å falle for fristelsen til å optimalisere det tallet. “I denne kodebasen skal vi ha 100% code coverage”, eller enda værre “i dette selskapet skal all kode ha code coverage på 100%”. Det er en dårlig idé av mange grunner, en av dem er at det er ganske enkelt å skrive dårlige tester som dekker mye kode uten å være særlig nyttige.
Men det finnes mange gode grunner til å sjekke ut code-coverage. Jeg tenker på det som et nyttig verktøy når jeg skriver tester, ikke som et tall jeg skal prøve å få så høyt som mulig.
Ofte skriver jeg tester etter jeg har skrevet koden (selv om test-først er et nyttig verktøy er det ikke noe som alltid fungerer). Da er det veldig nyttig å se på code-coverage før og etter jeg har skrevet en test. Hvilke del av koden var rød før, men blir kjørt nå. Stemmer det med det jeg trodde skulle skje? Om ikke, så betyr det kanskje at min mentale modell ikke stemmer med koden. Det er en gyllen anledning til å oppdatere min mentale modell til å bli bedre.
Skal jeg gjøre en refaktorering er det ofte nyttig å starte med å se på hvilke deler av den gamle koden som ikke er testet, og prøve å skrive tester for den.
Har jeg en bit kode som jeg tenker jeg har testet ut alle varianter av, titter jeg gjerne på code coverage. Kanskje får jeg meg noen overraskelser. Om jeg ser noe kode som er rødt, hva betyr det? Er det feil i testene, mangler jeg kanskje en test? Eller er det feil i koden? Kanskje jeg har en kodebit som ikke trengs?
Hvis jeg trenger en pause en dag, og har lyst til å gjøre noe annet kan jeg bruke litt tid på å se over code-coverage-rapporten for kodebasen jeg jobber i. Se om jeg finner noe kode som jeg mener burde vært testet, men ikke er det. Prøver å lage en test som gjør at koden kjører. Sjekker ut code-coverage på nytt, endret det seg?
Om jeg ikke klarer å lage en test som kjører koden, kanskje koden ikke trengs?
Hvilken kode mener du er viktigst å teste?
Er det noe kode som ikke er så viktig å teste?
LUKE-3 - Risikoanalyse i flere land
Noe av det beste jeg vet er å se på problemer fra forskjellige vinklinger. Den gaven håper jeg å kunne gi videre til dere i min juleluke. Jeg skal fortelle om to vinklinger risikoanalyse kan ha. Grovt forenklet som den franske 🇫🇷 og den tyske 🇩🇪.
Risikoanalyse viktig på en måte som avslører verdiene våre, angår samfunnet, og som mange derfor har en mening om. Hva er risikoen ved vaksinering, å legge en motorvei gjennom byen eller å utsette byggingen av et nytt sykehus? På et eller annet rom, eller kanskje i en mailboks, ligger en stor bunke med ark. I et møterom i tredje etasje går noen gjennom en powerpoint presentasjon med kule grafer og Microsoft fonter.
Her kommer to typer slides du lett kunne se i en sånn bunke. Hver og en knyttet til et land, så blir det lettere for deg å huske dem i ettertid. Begge brukes når det kommer til risikovurderinger av transportsystemer.
GAMAB 🇫🇷
GAMAB er en forkortelse for Globalement Au Moins Aussi Bon1, og er kanskje noe av det franskeste du kan si? Det oversetter til noe som: “Som helhet, skal systemet være minst like bra”. Så vi ønsker alltid å betrakte systemets risiko som en helhet. Alt vi gjør med systemet burde alltid være like bra, eller bedre som det alltid har vært. Regner med det finnes en annen metode for å se på nye systemer, men har ikke sjekket.
MEM 🇩🇪
I Tyskland er det vanlig å bruke “Minimum Endogenous Mortality”. Tyskerne ser på systemets bidrag til dødelighet, gjennom noe de kaller “Teknologiske dødsfall”. Kortfattet er dette dødsfall som skyldes systemet ditt, eller effekter av systemet ditt. Maskinulykker, ting du bare gjør på det stedet (sportsulykker også), defineres med bokstaven R og måles i dødsfall per person per år.
Vi lager oss en baseline Rm for den gruppen mennesker som har lavest dødelighet. Dette tallet er lavest for de av oss mellom 5 og 15 år. Så setter vi oss regelen at systemene våre ikke får lov til å øke dødeligheten til denne gruppen betraktelig. Det er rett og slett regelen for MEM. Nå mangler vi bare noen tall, så si at vi har:
- Rm = 2*10^-4 dødsfall per person per år
- Maks økning = 10^-5 dødsfall per person per år
Så er risikovurderingen din basert på hvor mange dødsfall du ser for deg per person per år.
Samme problem, to løsninger
Så skal vi sette i gang med den utbedringen vi planla for transportsystemet vårt? Vel, det spørs litt. Er den bedre enn den gamle, eller går den over smerteterskelen vår?
BONUS
For de av dere som ikke har fått nok, så finnes det mange flere måter å se på risiko. En av mine favoritter er et FN prinsipp vedtatt i 1992 i Rio de Janeiro. The Precautionary Principle:
Where there are threats of serious or irreversible environmental damage, lack of full scientific certainty shall not be used as a reason for postponing effective measures to prevent degradation
Eller i mine ord:
The absence of evidence, is not the evidence of absence.
glɔbaləmət‿ o mwɛ̃z‿ osi bõ, for fonetiske nerder.↩︎
LUKE-2 - Headache
I shouldn’t be responsible for what I say
Someone else should be responsible for what I say
There will always be baskets and benches
The cow is for land and the horse is for water
Dette er et utdrag fra mitt favoritt-album fra 2023. Et overraskende tilskudd på lista, delvis fordi albumet bare dukket opp, men mest fordi det tilhører sjangeren “spoken word”. Eller poesi eller monolog, over beats. Ok, så er det ikke så langt unna hiphop, og jeg er fan av produsenten, Vegyn, fra før, men likevel, dette er noe helt nytt for meg. En varm, elegant og britisk mannlig stemme fører meg gjennom en konstant strøm av store og små tanker, og forskrudde anekdoter og refleksjoner. Det henger ofte ikke på greip, men samtidig så har nettopp ordene truffet meg, som musikk-ord sjeldent gjør (jeg er opptatt av alt annet enn tekst når jeg hører på musikk), og ved et par anledninger har jeg til og med grått en skvett. Så det har vært en opplevelse av at, poesi kanskje er noe for meg?
Jeg skriver dog ikke om Headache for å gi en anmeldelse, men fordi jeg plutselig mye senere oppdaget noe som liksom forkludret denne fine oppdagelsen. Det har seg nemlig sånn at stemmen som bærer hele opplevelsen er AI-generert. Og det ble jeg rett og slett skuffa over å høre. Jeg hadde jo blitt kompis med denne kloke fortelleren over timesvis med lytting, og jeg følte han formidlet nære, intime opplevelser så ekte, og så sårt. Jeg kjente på nostalgi, og følelser jeg kunne relatere på et intuitivt plan. Da kan det hende at jeg plutselig følte meg litt snytt. Premissene er på en måte urettferdige. På den annen side, hva har det å si? Var ikke opplevelsen min det samme? Burde jeg være glad for at jeg ikke visste om det?
Dette er interessant, fordi det belyser hva vi (jeg) verdsetter med kunst. Vi er fortsatt inne i en tid der man ikke ønsker å skryte av at man har brukt AI til å skape noe. Blant annet fordi det faktum at noen har lagt energi, innsats, kompetanse og erfaring inn i et stykke arbeid, er noe vi anser som verdifullt og viktig i den kunsten vi konsumerer. Vi vil ikke like et million-maleri bedre, dersom vi får vite at det var slengt sammen på 15 minutter, og for ordens skyld, det var det antakeligvis heller ikke. I tillegg til fraværet av det menneskelige, er det nettopp opplevelsen av at AI-verktøy er en slags “snarvei” til et ferdig resultat som vi ikke synes hører hjemme i kunsten.
Jeg har forøvrig ingen agenda eller ønske om å nå en konklusjon med disse refleksjonene. Det bør noteres at selve teksten, de rare fortellingene i Headache-universet, er skrevet av en ekte person (poet) ved navn Francis Hornsby Clark. Det har mye å si. Det er en stor forskjell på å bruke AI som et hjelpemiddel for å formidle, og det å la AI fullt og holdent gjøre kreativt arbeid for deg. Så jeg skal fortsette å høre på Headache, og jeg synes du skal sjekke det ut. Selv om jeg savner bildet av den ekte, britiske fortelleren, som aldri fantes. Beklager at du nå vet det.
LUKE-1 - Jeg liker norske valg
Jeg liker Stortingsvalget. Selve demokratiet og sånt er ganske ålreit, men nå tenker jeg på selve prosessen rundt det å velge representanter til nasjonale forsamlinger. Mange U-land som the United Kingdom og USA har ganske dårlige mekanismer for å velge sine representanter. Her til lands syntes jeg vi har fått det bedre til. Jeg tenkte min lukegave til dere kunne vært å forklare hvorfor.
Lokal representasjon vs hele landet.
I de fleste er land er nasjonaleforsamlingen bygget opp av representanter fra mange lokale valgkretser. Storbritannia sitt underhus består av 650 delegater som representerer én valgkrets hver. Dette betyr at den som får flest stemmer i hver valgkrets, representerer den valgkretsen. Dette er ikke bra! Se for deg en valgkrets med to partier hvor det ene vinner med 52% av stemmene. Da er i praksis 48% av valgkretsen ikke representert, og velgerne av det partiet må bare håpe at deres parti klarer å gjøre det opp for det andre steder.
Dette systemet: first past the post, winner takes all har mange uheldige konsekvenser. Det heller mot et to-parti system som sjeldent klarer å representere befolkningen særlig godt. Det fører også til forkalkninger: det er ikke noe vits for partier å kjempe over “sikre” valgkretser, hvor et parti vinner med f.eks 75% av stemmene. Representanter fra slike kretser sitter gjerne over mange perioder og mister kontakten med kretsen sin og slutter å kjempe for dem.
Vi ser dette veldig tydelig i USA når det skal velges president. Det er ikke noe poeng for demokratene å bruke masse tid og ressurser på f.eks South Carolina hvor republikanerne får jevnt over >60% av stemmene. Mesteparten av tiden, pengene og løftene går til vippestatene hvor det faktisk er mulig å vinne alle delegatene fra den staten.
Løsning: flere representanter fra samme valgkrets!
Det er egentlig ikke verre enn det. I Norge har vi 19 valgkretser som til sammen sender 150 mandater til Stortinget. Disse mandatene er fordelt på befolkning og areal. Siden samme valgkrets får sende flere delegater, kan man matche disse opp mot hvordan kretsen stemte som helhet, heller enn å la vinneren ta alle mandatene. Dette er heller ikke perfekt siden mindre partier som ikke er store nok til å få nok stemmer til ett mandat blir ikke representert. Men det løser vi (nesten) med:
Sperregrensen: The secret sauce
Et av knepene vi gjør i Norge som jeg syntes er ordentlig kult er at vi har 19 såkalte utjevningsmandater (en per valgkrets). Etter at alle stemmene er talt opp og de 150 distriktsmandatene er fordelt, ser vi hvordan denne mandatfordelingen sammenligner med hvordan hele landet stemte. Det som ofte skjer da er at mindre partier som gjerne ikke er store nok i hver enkelt valgkrets, men er ganske populær på nasjonal basis (fler enn 4% stemte på dem) er underrepresentert på Stortinget.
Da har vi en algoritme som fordeler utjevningsmandatene slik at Stortinget i større grad matcher hvordan hele befolkningen faktisk stemte. Dette gjør at mindre partier likevel blir representert, og at din stemme på et av disse partiene likevel har noe å si. Venstre fikk f.eks utjevningsmandatet for Sogn og Fjordane, selv om de bare fikk 2.3% av stemmene der.
Så bruk stemmen din, den teller mer enn du tror!
OLORM-45:
--scale i Docker Compose
I dag lærte jeg noe kult!
Docker Compose har et --scale-argument man kan bruke til
å skru av en tjeneste. Supernyttig når jeg vil kjøre én tjeneste manuelt
(feks med go run eller yarn dev), men vil ha
resten i Docker.
Eksempel:
docker compose up --scale api=0 --scale analytics=0Så kjører vi api og analytics manuelt i
hver sin terminal:
(cd api && make run)
(cd analytics && make run)Tidligere har jeg kommentert ut og inn tjenester av
docker-compose.yml. Det har jeg aldri helt likt. Det er
alltid en sjanse for å comitte sånne endringer og ødelegge for
andre.
Kudos til Christian Duvholt som skrev Docker Compose-filen som gjorde alt dette mulig.
—Teodor, 2023-11-24
OLORM-44: HTMX
Jeg er for tiden urimelig opptatt av HTMX. Hvorfor?
- Hypertekst er en enkel mental modell som lener seg på at nettlesere tilbyr interaktivitet dersom du lager hyperdokumenter.
- Med HTMX kan du skrive ren statisk HTML så lenge det holder, og innføre litt og litt dynamikk der det trengs.
Dette gjør at du kan levere interaktive nettsider i alle programmeringsspråk som egner seg til å skrive en HTTP-server.
Du slipper i tillegg å håndtere tilstand på klienten: med HTMX har du kun tilstand på serveren.
Da visker vi bort skillet mellom server og klient. Du lager en webapplikasjon, og kan bruke én teknologi for å lage alt.
Denne fordelen får du også hvis du allerede bruker Javascript, språket som kan kjøre direkte i nettleseren: i stedet for å skrive en server og en klient, skriver du kun én webapplikasjon. Én applikasjon er lettere å vedlikeholde enn to.
Jeg synes ofte det er rart å snakke med folk om hypertekst. Jeg synes hypertekst er en ufattelig god teknologi—vi bygger opp internett som et sett med dokumenter, der dokumenter kan lenke til andre dokumenter. Informasjon står først, systemer og kode er en detalj. Dokumentene er det vi leverer. Dokumentene er det brukerne våre tar i.
Men å bruke HTMX krever at man tenker nytt! Som ofte er tilfellet når man jobber med teknologi. Det er mange nye ting man kan lære seg, hvilken bør man velge? For 2024, vurdér HTMX. Ordet “hypertekst” ble brukt av Ted Nelson i 1967. Jeg har tro på en comeback.
Færre, enklere verktøy for en enklere utviklerhverdag.
Lær mer om htmx på htmx.org.
—Teodor
OLORM-43: Fire akser for å vurdere kvalitet—presisjon, generalitet, innovativitet og levendehet
Avatar får terningkast 6! Det er en dritkul film!
Men kul film for hvem, til hva? Filmkritikere fyller på med tekst som beskriver hva de likte, hva de ikke likte, og hva slags stemning man fikk av å se filmen.
Hvordan sammenlikner du Mona Lisa med The Emperor’s Old Clothes, turing-forelesningen til Tony Hoare? Gir du begge 6/6 og sier deg ferdig? Eller setter du deg ned og skriver tekst for å dele din egen opplevelse av Mona Lisa og The Emperor’s Old Clothes?
Når filosofer snakker om hvordan vi beskrver ting, bruker de ofte fenomenologi eller intersubjektivitet for å unngå fella om “alt er subjektivt, derfor kan vi ikke si noe som helst”. Men fenomenologiske og intersubjektive betraktninger er ofte lange, og vanskelige å lese.
Jeg foreslår i stedet at vi velger oss fire akser med verdier mellom 0 og 1.
Presisjon, generalitet, innovativitet og levendehet: fire akser for å klassifisere tekst
- Presisjon. Er det tydelig hva som formuleres? Eller er det åpent for tolkning? En god tekstbok i fysikk er presis. Et godt skjønnliterært verk er nødvendigvis mindre presist.
- Generalitet. Snakker vi om generelle sannheter om mennesker? Eller uttaler vi oss om et smalere domene? Er dette interessant for noen eller mange? Evolusjonsteori lar deg uttale deg om en bred samling domener. Hvordan vi lager mikrochipper som bruker layout i 3D til å gi lokalitet for å lage raskere CPU-er er smalere.
- Innovativitet. Er det som presenteres allmenkjent, eller kommer vi faktisk med ny kunnskap her? En tekstbok om matematikk til bruk på videregående skoler skal ikke presentere et innovativt pensum: vi en solid gjennomgang av kjent materie. En person som forsker på tallteori må kunne uttale seg om noe nytt. Ellers er det ikke forskning!
- Levendehet. Blomstrer teksten, eller er det sten død? Vi vil at standup-komedie sjokkerer oss. Vi vil ha kunst som beveger oss. Vi vil føle noe når vi er i naturen. Men vi vil ikke bli overrasket over at taket vårt faller ned. At pengene våre i banken blir borte. At skip synker. Noen tekster lever, får oss til å føle.
The War of Art vurdert etter presisjon, generalitet, innovativitet og levendehet
Jeg har gitt boka The War of Art av Steven Pressfield 5/5 stjerner for Goodreads, sammen med kommentaren:
Tacky title. First time I tried reading it I hated it after one chapter and put it away.
It’s opinionated and unapologetic. It might offend your feelings.
But it’s honest. Good luck.
I dag vil jeg vurdere den etter presisjon, generalitet, innovativitet og levendehet fordi jeg tror det gir mer dybde enn stjerner.
Presisjon: 0.7. Pressfield skriver sabla godt, men språket hans blomster av allegorier. Dette er litteratur, ikke forskning. I blant er det uklart ha han mener. Men den åpningen gir det mulighet til å reflektere.
Generalitet: 0.5. Boka handler om å skape. Den skriver på en måte som fint er mulig å kjenne seg igjen i. Men den polariserer. Jeg tror ikke boka er for alle.
Innovativitet: 0.9. Ideene i boka var nye for meg da jeg leste boka (på anbefaling fra Sean Percival). Du skal skape, ellers kan du gi opp at det skjer nye, uvendede ting.
Levendehet: 0.99. The War of Art er en fryd å lese, og en reise i god historiefortelling. Jeg blir mer gira av å ha lest et kapittel. Det hender jeg plukker opp kapitler og leser kapitlene på nytt bare for å få med meg stemingen kapittelet setter meg i. 0.99 er den høyeste scoren på levendehet jeg har gitt noen tekst noen sinne.
Husk å tagge vurderinger med dato.
Jeg skrev vurderte The War of Art på 2023-10-15 (søndag 15. oktober 2023). Kanskje jeg endrer på hva jeg mener! At du endrer på hvordan du vurderer en tekst sier noe om hvordan du endrer deg. Spennende greier! For å ta høyde for dette i et databaseskjema, er det fint å legge ved en datotagg. Når er denne vurderingen gjort? Og av hvem?
Vi gjør subjektive vurderinger på et punkt i tid. Så kan vi heller mene andre ting senere hvis vi har endret oss siden sist.
Hvordan vurderer du tekst?
Når du har sett en film, lest en bok eller vært på slam-poesi, hvordan framstår det for deg at du har vært på noe bra? Hva er det du setter pris på? Dette er jeg meganysgjerrig på. Jeg tror aksene mine speiler personligeheten min ganske tydelig. Hvordan passer de for deg? Ville du lagt til andre akser? Svar i tråd!
sed matching og betinget utførelse
“Match X og print Y=f(X)” er noe man ofte ønsker å gjøre. Eksempel:
echo 'Her er noe eksempeldata med
en linje med referanse til ref_123_bg og
en til ref_436_md osv.' > filSi at vi vil:
- Finn alle “
ref_<ID>_<SUFFIX>” - Print
<SUFFIX>:<ID>
En enlinjes sed-kommando for dette er:
# Søkeuttrykk Erstatning
# ┌─┴─────────────────────┐ ┌┴──┐
sed -Ee 's/.*ref_([0-9]+)_([a-z]+).*/\2:\1/;t' -e d <fil
bg:123
md:436Det jeg liker med denne er at vi bare trenger ett regulært uttrykk i skriptet.
Kommandoen t er det magiske her, det er
seds eneste kommando for betinget flytkontroll.

Fra dagens manual kan vi tilføye:
If label is not specified, branch to the end of the script.
Dette er grunnen til de to -e option-argumentene; vi
trenger et “linjeskift” for å avslutte t uten
label-argument.
Skrevet ut ser skriptet slik ut:
sed -E '
s/.*ref_([0-9]+)_([a-z]+).*/\2:\1/ # erstatt *ref_X_Y* med Y:X
t # hvis erstatting skjedde, hopp til <label> (tom = slutten)
d # slett linje (hvis ikke hoppet over av forrige funksjon)
' # de linjene som ikke slettes vil som default printesDa jeg lærte denne komboen av -e og t (og
b, betingelsesløs forgrening) syntes jeg den var akkurat så
sær at jeg måtte legge den i mitt hjerte, og dele den med dere i
dag.
Hva synes du?
—Richard Tingstad
P.S. Sett sammen med hold space omtalt tidligere så kan man kanskje skimte her at programmeringsspråket til sed er Turing-komplett.
Kotlin?
Nå driver jeg og lærer meg Kotlin i et nytt prosjekt.
Jeg er usikker på om jeg liker det.
Kotlin i seg selv virker ok. Men jeg sitter for øyeblikket med Spring Boot, som jeg definitivt ikke liker.
Jeg har lurt på om Kotlin er aller kulest om du stort sett har jobbet i Java tidligere.
Jeg har savnet IDE-støtte for automatiske kodeendringer, håper det blir mer av det på meg når jeg får brukt Kotlin mer.
OLORM-40: trust, but verify
Betyr det å stole på folk å slippe kontrollen?
Det er lite givende å hjelpe til når en person tviholder på all kontroll, og vil ta alle beslutningene. Når en person skal bestemme alt, er det lite plass til mitt bidrag.
Én mulighet er å slippe kontrollen fullstendig. Før gjorde jeg jobben, nå er det noen andre som gjør jobben. Det får bli hva det blir.
Ulempen med å slippe kontrollen fullstendig er at man ikke får en overgangsperiode. Kunnskap blir borte.
Et alternativ er å gi tillit, men verifisere hva som skjedde.
Gi rom til at folk kan gjøre sitt beste. Bidra etter beste evne selv. Så ser du hva som skjer. Og etterpå verifiserer du om det som skjedde var det du ønsket at skulle skje. Er du fornøyd eller misfornøyd? I begge tilfeller bør du kanskje snakke med personen som gjorde jobben.
—Teodor
Frasen “trust, but verify” ble mye brukt av Reagan under avtalene for nedrustning av atomvåpen på 80-tallet. Frasen har sin egen side både på Wikipedia og på Wiktionary. Jeg har også skrevet om grad av kontroll i lederskap i kontekst av et Elm-kurs jeg lagde og holdt for Kodeklubben Oslo i 2017.
GitHub knakk byggene våre
I går feilet plutselig flere av våre CI-bygg uten tydelig årsak.
Etter tur innom noen blindgater der vår kode var endret — men tilsynelatende ikke relevant — fant jeg til slutt årsaken etter kjøring av flere modifiserte test-bygg for feilsøking.
Vi bruker i mange GitHub Workflows:
runs-on: ubuntu-latest(Eller ubuntu-22.04 eller ubuntu-20.04, det
samme gjelder.)
Disse runner-image’ene fikk nylig en oppgradering: Ubuntu 22.04 (20230903) Image Update, 20.04 (20230903) Image Update, der de endret blant annet:
| Category | Tool name | Previous (20230821.1.0) | Current (20230903.1.0) |
|---|---|---|---|
| Tools | Compose v2 | 2.20.3 | 2.21.0 |
Docker Compose release notes 2.21.0 sier at:
The format of
docker compose psanddocker compose ps --format=jsonchanged to better align with docker ps output.
Sistnevnte kommando returnerte tidligere en json-array, men returnerer nå linjeseparerte json-objekter. Dette er en breaking change (ikke-bakoverkompatibel endring).
Jeg synes dette er en litt kjedelig situasjon. At Docker Compose brekker APIet sitt så lemfeldig. At vi har ikke reproduserbare bygg fordi bakken endrer seg under føttene våre. At dette er normalsituasjonen?
Hva tenker du?
—Richard Tingstad
Start på slutten
I utvikling følger vi ofte en Kanban-inspirert prosess med tavle inndelt i kolonner med oppgave-lapper:
| innkommende | pågående | verifisering | ferdig |
|---|---|---|---|
| ny sak | |||
| fiks | |||
| oppgave |
Kanban sier: Begrens antall oppgaver under arbeid!
Vi vet jo alle at for mange samtidige oppgaver skaper krevende kontekstbytter, generell fare for kaos, og økt total tidsbruk per oppgave — så dette er et fornuftig råd.
En vakker innsikt er å alltid lese tavlen fra høyre til venste (systemet er pull-basert, ikke push-basert). Hvilken oppgave er nærmest å være ferdig? En ferdig oppgave leverer verdi og innsikt, og frigjør plass til neste oppgave.
Jeg finner kvalitet i at team-medlemmer følger denne prioriteringen med “sist først”. Det betyr at jeg synes det er verdifult at en pull-request tas relativt raskt, på bekostning av å fortsette med sin egen koding e.l.
Tenk gjerne: “Hva kan jeg gjøre denne morgenen for å unblocke en oppgave?”
Når en ny oppgave skal påbegynnes (vi har en del individuell frihet ved valg av uløst oppgave) finner jeg kvalitet i at man velger “kjipe” bugfiks-oppgaver fremfor kul ny feature. Selv om disse er likestilt “horisontalt” på tavla, tenker jeg at bugfiksen er mer “høyrestilt” (= høyere stilt?) enn en ny feature.
Men så må man selvfølgelig passe på at man også bruker nok tid på de mer langsiktige oppgavene.
Relatert mikroblogg av undertegnede: Fart i utvikling?
Hva tenker du, har du noen andre tommelfingerregler du liker? Er du uenig i mine tanker? Det er lov, jeg er det ofte selv!
—Richard Tingstad
JALS-9
For å gjøre kodeendringer i hovedbranchen i Vake må det lages PR. For disse PR-ene bruker vi Github Action workflows som kjører tester/sjekker på kodebasen som må bli grønne for å kunne merge endringene. Testene omfatter logikk (Python tester), kodeformat, typing, at docker imaget bygger m.m. Kodeendringene i en PR må altså gjennom alle disse stegene for å bli godkjent.
Grunnen til at vi “enforcer” dette på alle (via PR) er at det holder kodebasen konsistent, mer leselig og forhåpentligvis fri for bugs. Siden det meste går i Python syns vi det er spesielt greit å være litt strenge. For det som går på kodeformat, typing osv. gjør vi tilsvarende sjekker lokalt gjennom pre-commits for å raskere luke ut småting før man pusher ting remote (denne har vi holdt optional, men alle (?) bruker det).
Ulempen med denne flyten er at det kan ta lengre tid å få inn en PR, og innimellom blir man utålmodig, ventende på sjekker man kanskje vet er helt unødvendig for endringen man prøver å gjøre. For å gjøre dette mer effektivt har vi laget en GA jobb som sjekker hvilke filtyper som er endret i PR-en, og så blir de andre sjekkene utført på bakgrunn av dette. Da slipper vi f.eks. å vente på å sjekke om Docker imaget bygger hvis man kun har gjort en endring i dokumentasjonen.
I sum syns vi det er greit med sjekkene selv om det tar litt tid. Hva tenker dere andre, hvordan gjøres det (eller ikke) i deres team?
OLORM-37: Expected/actual i hypotesetesting
Jeg har flere ganger prøvd å få hjelp til bruk av Open Source-teknologi, og fått følgende svar i fleisen: “Not clear what expected/actual is. What are you trying to achieve? What are you observing?”
Først skjønte jeg ikke hvorfor jeg fikk dette spørsmålet. Er ikke svaret åpenbart? Koden min krasjer. Jeg vil at den ikke skal krasje.
Men. 🥁 🥁 🥁 Det finnes uendelig antall måter koden kan ikke krasje på! Hvilken er det du egentlig vil ha?
Dette gjelder også hypotesetesting! Hvis du går ut til folk som kanskje skal bruke produktet du lager og spør “er dette bra?”, vet du ikke hva du får svar på.
Jeg liker å formulere en hypotese først. Hypotesen prioriterer. Den sier noe om hva som er viktigst å finne ut. Så kan jeg teste den.
OJ JEG ER KONSULENT
“Allerede den første uken på studiet ble vi introdusert til konsulenthverdagen gjennom linjeforeningens hovedsamarbeidspartner, Bekk. Og jeg sitter igjen med inntrykket av at fra det tidspunktet var det nok få som så seg tilbake; jobbtilbud og sommerinternships hos konsulenthus sto øverst på listen over ønskede arbeidsgivere. Dette kan også sees i Abakus sin utmatrikuleringsundersøkelse for 2022, hvor fire av topp fem ideelle arbeidsgivere er konsulenthus, og den siste er Google. (Det er kult å merke seg at Iterate faktisk er på fjerdeplass her). Men gir egentlig det å lokke med gratis mat og alkohol det riktige inntrykket av hva en konsulenthverdag innebærer? Har studenter og nyutdannede egentlig tenkt over hva dette innebærer? Jeg vet i hvert fall med meg selv at jeg ikke har gjort det, og har tenkt flere ganger den første måneden:”Oj! Jeg er konsulent”.”
Første forespeilet oppdrag
Når en fra salg kom til oss (Olav og meg) første gang, skvatt jeg litt til. Han presenterte et potensielt oppdrag hos at av Iterate sine porteføljeselskapet, noe som fikk meg til å sukke litt. Ikke fordi prosjektet ikke var spennende – muligheten til å jobbe med mindre selskaper var en av de tingene jeg så på som en positiv side ved Iterate. Sukket var uavhengig av oppdraget, og heller relatert til det å være konsulent. For dette oppdraget innebar å sitte på kontorene til selskapet, noe som er et faktum for konsulenter, men som jeg ikke hadde ofret en tanke. Jeg hadde på dette tidspunktet brukt tre gode uker på å bli kjent med folk i Iterate og å komme godt i gang med lunsjslabberas. Men nå skulle jeg plutselig ikke møte disse menneskene på flere uker, mens jeg var ute på oppdrag. Det er en selvfølge man kanskje burde ha tenkt på, men det hadde jeg altså ikke gjort, og skvatt litt der og da.
Hoppe ut på dypet
Den andre ‘oj’-en kom da jeg plutselig snublet over et driftsoppdrag fra en kollega. Jeg har alltid tenkt at dette med å hoppe ut i det dype er måten jeg lærer best på, men denne gangen slo tanken meg: “Oj, jeg er konsulent.” Og her har jeg muligheten til å trå feil og faktisk gjøre ting verre for kunden. Jeg ble også stilt spørsmålet: “Hva vil du anbefale for vår kunde?” Tanken slo meg at som konsulent skal jeg faktisk kunne gi råd om hvordan noen skal utvikle sin bedrift, en kanskje litt skremmende oppgave, i hvert fall som nyutdannet.
Misforstå meg rett. Jeg elsker min nye tilværelse i Iterate, og ser mange positive sider ved å jobbe som konsulent. Men nå merker jeg at dette begynner å bli langt. Så det får jeg heller ta i en ny ‘oj’ om litt.
-Johan
sed reverse
En mye brukt kommando for å reversere linjerekkefølgen i en fil er følgende:
printf 'R\nE\nV\n' | sed -n '1!G;h;$p'
V
E
RSiden sed-kommandoene er veldig konsise kan de fremstå litt kryptiske. Her gir jeg en forklaring.
sed virker sånn at for hver input-linje evalueres kommandoene.
Ved kjøring kalles linjen under behandling for “pattern space”. Det finnes en tilleggsverdi kalt “hold space” (i utgangspunktet tom), som man kan lagre til om man vil.
Option -n betyr at sed ikke skal printe noe
output med mindre vi kaller p. Uten -n printes
pattern space etter hver behandlede linje.
1!G;h;$p kan utvides til:
1!{ # linjenr != 1
G # hent og append hold space til pattern space
}
h # lagre (pattern space) til hold space (overskriv)
${ # siste linje
p # print (pattern space)
}Etter hver kommando ser verdiene slik ut:
| linje | kommando | pattern space | hold space | kommentar |
|---|---|---|---|---|
| R | 1!G | R | kjører ikke | |
| R | h | R | R | |
| R | $p | R | R | kjører ikke |
| E | 1!G | E\nR | R | |
| E | h | E\nR | E\nR | |
| E | $p | E\nR | E\nR | kjører ikke |
| V | 1!G | V\nE\nR | E\nR | |
| V | h | V\nE\nR | V\nE\nR | |
| V | $p | V\nE\nR | V\nE\nR |
Så hver linje blir i praksis prepend’et de forrige, litt som en stack.
Håper sed nå er mindre magisk!
Send gjerne spørsmål eller kommentarer til Richard Tingstad :)
OJ JEG ER NY
Det tok sin tid, men endelig kan jeg publisere det første innlegget på min (og Johans) egne mikroblogg: OJ. De siste ukene har vi jobbet med å lage funksjonalitet for å faktisk kunne gjøre nettopp dette, så dette innlegget blir litt om erfaringer fra denne jobben, og en test på at det vi har laget faktisk funker.
Prosessen gikk i grove trekk slik:
- Jeg har lyst til å lage en feature
- Innse at kodebase ikke støtter dette særlig bra
- Finne ut hva jeg må lage og hva jeg må endre
- Begynne å implementere (litt..) til noe annet må endres for å støtte den nye endringen
- Endre systemdesign..? Tenke.. diskutere.. tenke.. hvorfor er dette slik?.. diskutere.. OK (for nå).
- Implementer (litt til..)
- Gjente steg 3-5 en del ganger.
- Ting fungerer endelig (forhåpentligvis), men ser stort sett uendret ut.
Det var det, velkommen til OJ (om alt funker)! Som i de andre mikrobloggene gikk tematikken her brått inn på refaktorering.
Kommentarer, og gjerne tips til nyutdannet teknolog tas i mot med glede.
Olav
Enums i postgres, trenger jeg det egentlig?
Jeg har eksperimentert med å bruke enums i postgres for kolonner som kun kan ha få gitt versjoner, som for eksempel hvilken state eller type noe er. Det er fint for å sørge for at databasen aldri inneholder noen verdier vi ikke forventer i backenden, men å endre på en enum har vist seg å være litt vanskelig. Å endre på enums i postgres ble introdusert i versjon 9.1, men siden jeg gjør databasemigrasjoner med sqlx som kjører i en transaction, får jeg ikke lov til å endre på enums direkte. Jeg må lage en ny og gjøre en rekke operasjoner for å få endre på noe
ALTER TYPE subscripton_type_enum RENAME TO subscripton_type_enum_old;
CREATE TYPE subscripton_type_enum AS ENUM ('custom', 'free', 'basic', 'designer', 'professional');
ALTER TABLE design_studio_checkout_sessions
ALTER COLUMN subscription_type DROP DEFAULT,
ALTER COLUMN subscription_type TYPE subscripton_type_enum
USING subscription_type::text::subscripton_type_enum,
ALTER COLUMN subscription_type SET DEFAULT 'custom';
ALTER TABLE design_studio_subscriptions
ALTER COLUMN subscription_type DROP DEFAULT,
ALTER COLUMN subscription_type TYPE subscripton_type_enum
USING subscription_type::text::subscripton_type_enum,
ALTER COLUMN subscription_type SET DEFAULT 'custom';
DROP TYPE subscripton_type_enum_old;Siden backend-koden er skrevet i Rust og det naturlig nok kun er den som snakker med databasen, tenker jeg at det kanskje er like greit å holde seg til å kun definere enums i backenden og ikke i databasen i tillegg.
Trenger vi dokumentasjon?
Jeg kom akkurat ut fra nok et møte om en løsning som har integrasjon mot to tredjeparter.
Begge har vi eksisterende integrasjoner mot, men nå skal vi buke noe ny data, noen nye parametre, og ny versjon av noen endepunkt.
Jeg synes det er utfordrende at det er lite og mangelfull dokumentasjon.
Hva betyr egentlig feltet nId i respons-dataen? Er
feltet externalX alltid satt, eller kun for noen typer?
Noe av dette er dokumentert på side 13 av et arbeidsdokument fra i fjor. Annet er “dokumentert” i et svar i en av hundrevis av Slack-tråder.
“Alle” misliker å skrive og oppdatere dokumentasjon, og alle hater utdatert og misvisende dokumentasjon.
“Koden er dokumentasjonen,” sies det. Den er aldri utdatert(?). Men for tredjeparts APIer har vi ikke koden, vi har bare stikkprøver av data og gjetninger.
Så jeg vi si: ja, vi trenger dokumentasjon.
Jeg tror vi hadde spart mange møter, duplikate Slack- og epost-spørsmål hvis vi hadde det. Hvis ikke tredjeparten leverer dokumentasjon, kanskje vi skulle dokumentert APIet på vår side, som best vi kan.
—Richard Tingstad
OLORM-33: Et første møte med CICD
Alle kan Github actions, ikke sant? Og YAML, det må da folk ha hørt om.
Nope! Vi utviklere må lære nye ting hver dag. Det er en fantastisk mulighet; hvis vi kontinuerlig lærer nye ting, kan vi bli skikkelig flinke. Det er også en byrde: det finnes så ufattelig mange ting vi må lære oss.
Jeg har nettopp satt opp CICD på Mikrobloggeriet. Her er mine erfaringer.
Hva er CICD?
Først, la oss definere hva vi snakker om.
- Continuous integration (CI) handler om at vi kontinuerlig sjekker om systemet vårt fungerer når vi endrer det. I Mikrobloggeriet betyr CI “Vi kjører alle enhetstestene på alle commits”.
- Continuous delivery (CD) handler om at vi kontinuerlig oppdaterer det kjørende systemet. Vi kan sette koden vår i produksjon når vi vil. I Mikrobloggeriet betyr CD “Vi setter automatisk alle endringer i produksjon hvis testene er grønne”.
Om å kode på mikrobloggeriet
Når jeg har jobbet med Mikrobloggeriet-koden har jeg fulgt noen prinsipper:
- Vi skal se produktverdi før vi legger mye jobb i koden. Hvis ingen vil skrive mikroblogger, skal vi heller ikke lage et stort system for mikroblogging.
- I koden skal vi vente med å abstrahere. Vi vil heller ha for spesifikk enn for abstrakt kode.
Jeg synes det har fungert bra til nå. Men det har gitt noen utfordringer:
- Vi lagde mikroblogg med 41 innlegg før vi skrev en eneste enhetstest.
- Da den første andre personen enn meg skulle prøve å spinne opp koden, ble det trøbbel.
Da er det på tide å sakke ned! Jeg ville da få til følgende:
- Kodebasen legger opp til at man kan skrive tester og jobbe mot testene lokalt.
- Testene kjører mot hver commit på Github (CI)
- Vi prodsetter automatisk kode når testene er grønne (CICD)
- Kodebasen inneholder ingen uferdig eller ubrukt kode (“clean code”)
Noen refleksjoner om CICD
Hva synes jeg om CICD etter å ha prøvd litt?
Utrolig fint å kunne lene seg på grønne tester i commit-loggen. Det gir meg ro!
Testene kjører dobbelt! Jeg kjører både testene gjennom Github Actions og i selve bygget (i Docker). Det føltes litt rart å velge det, er ikke dette duplisering? Jeg vil kjøre testene i en GH Action fordi da får jeg god tilbakemelding på hva, spesifikt som feiler. Og jeg kjører testene mine i Docker i bygget for å unngå at koden blir prodsatt hvis testene feiler. Jeg kunne kanskje sagt at “prodsetting skal vente på at alle sjekker er ferdig”. Men jeg synes det jeg har funker helt fint, og nå vet jeg i tillegg at alle ganger jeg bygger med Docker lokalt er testene grønne.
Github Actions og YAML er noe man må lære seg! Her er en start:
For å starte med GH actions, legg til én fil:
.github/workflows/test.ymlHer er et minimalt grønt eksempel:
name: Run tests on: [push, pull_request] jobs: Testing: runs-on: ubuntu-latest steps: - run: echo success!Hvis du legger til denne i repoet ditt, bør du se en liten grønn prikk ved siden av commit-ene dine.
Her er et minmalt rødt eksempel:
name: Run tests on: [push, pull_request] jobs: Testing: runs-on: ubuntu-latest steps: - run: FAILEksempelet feiler fordi
FAILikke er en systemkommando. I stedet forrun: FAILkunne man kjørtrun: go test,run: npm testellerrun: clojure -A:run-tests. Da skalgo testgi returkode 0 hvis alt er OK, og noe annet enn 0 hvis testene feiler.
Er testing og CICD verdt innsatsen?
Min konklusjon så langt er ja. Hvis man ikke har god testdekning og kontroll på hvilke commits som er grønne og røde, blir det utrygt å skrive kode. Og når det er utrygt å endre kode, er det vanskeligere å komme framover på produktet.
Hva er dine erfaringer med CICD?
CICD er ikke noe vi lærer om på universitetet. Det var i alle fall ikke noe jeg var innom. CICD handler om hvordan vi jobber sammen i praksis.
- Har du vært på prosjekter hvor CI eller CD har latt deg jobbe mer effektivt? Hvorfor?
- Har du innført CI eller CD på et prosjekt noen gang? Hvordan har det vært?
Jeg vil gjerne høre! Dette er noe jeg tror det er lurt at vi snakker om og deler erfaringer om.
—Teodor
OLORM-32: Konsulentsalg av teknologer
Jeg skrev akkurat masse skryt om meg selv i et konsulenttilbud. På ett vis føles det helt feil.
Her maler vi med så bred pensel at all tekstur er borte. Her er en liste med teknologier! Her er masse greier jeg har gjort tidligere! Jeg lover at alle tingene jeg har gjort tidligere er skikkelig bra!
Så er det bra? Er det dårlig? Tja. Det er i alle fall nødvendig. Vi driver konsulentbedrift, og det er sånn konsulentsalg funker. Hvis de som kjøper folk de ikke er fornøyd med, kan de i alle fall si opp kontrakten. Men kanskje man faktisk blir fornøyd, selv om man får noe man ikke liker.
Go interface nil values
Vi brente oss på en Go-finurlighet igjen.
Vi returnerte interfacet io.Reader fra noen funksjoner,
og vi hadde en sjekk if reader == nil.
Dette virker noen ganger fint, og andre ganger ikke. Se følgende kode:
func main() {
var reader io.Reader = nil
fmt.Println(reader == nil) // true
var b *bytes.Reader = nil
fmt.Println(b == nil) // true
reader = b
fmt.Println(reader == nil) // false 🤯
}bytes.Reader implementerer io.Reader.
Derfor kopilerer dette uten problemer, og kjører også helt perfekt med
ulike verdier, bortsett fra akkurat den vist over.
Det viser seg at implementasjoner av interface er nil
kun hvis verdien og typen er nil.
Go FAQ har et innslag om dette og anbefaler bruk av interfaces i returtyper, selv om:
This situation can be confusing
De har ellers ingen gode løsninger utover:
Just keep in mind that if any concrete value has been stored in the interface, the interface will not be
nil.
Jeg synes dette var veldig overraskende og føler at Liskov Substitution Principle (LSP) blir brutt, men får bare prøve å ha dette i mente.
Send gjerne spørsmål eller kommentarer til Richard Tingstad :)
Anker-dato
Jeg lærte et nytt ord som jeg synes var interessant nok til å dele. En anker-dato (anchor date) brukes når man f. eks skal betale noe hver måned, men samtidig ta høyde for at ikke alle måneder er like lange.
Her er et eksempel: Et månedsabonnement begynner 31. januar, dette vil også være anker-datoen. Neste gang forfaller det 28. februar. Men når i mars skal det forfalle? Plusser vi på en måned fra siste dato ender vi opp med 28. mars, men det blir ikke riktig. Vi skal heller ta utgangspunkt i anker-datoen og plusse på to måneder. Riktig forfall blir da 31. mars.
Om argument-parsing i Shell
Det finnes noen utbredte konvensjoner som er veldig fint å støtte, som at det er lov å gruppere og sortere argumenter etter eget ønske (denne bloggposten anbefaler jeg):
program -i -t -a
program -it -a
program -taiDet er derfor nyttig å bruke hjelpe-kommando eller -bibliotek for å
lese argumenter. Fish har en ganske fin
argparse, som ligner på noe som finnes i mange
programmeringsspråk. Om Shell ble det sagt:
argparse. Synes det er skikkelig dritt i sh.
Hvordan kan man gjøre det i shell? De ulike shellene - Bash, Zsh, etc. - har sine egne fine løsninger. Man kan se på disse spsialtilfellene om man vil.
Nesten alle kommandolinje-konvensjonene ble etablert i tidlige
Unix-versjoner, på 70- eller 80-tallet. I 1986 kom Bourne Shell med en
nyere kommando for argumentlesing: getopts, og:
In 1995,
getoptswas included in the Single UNIX Specification [POSIX] […] As a result,getoptsis now available in shells including the Bourne shell, KornShell, Almquist shell, Bash and Zsh. — Wikipedia
Den er litt annerledes enn argparse, men virker
godt:
all=0
while getopts f:aV opt
do
case $opt in
V) version; exit;;
a) all=1;;
f) file="$OPTARG";;
?) printf "Usage: $0 [-a] [-f file] args\n or: $0 -V\n";;
esac
done
shift $((OPTIND - 1))Konklusjon
Med getopts i en while-løkke kan man enkelt
deklarere og lese options med (f:) og uten
(a,V) option-argument. Hvis man
klarer seg uten --long-options er det bare å nyte ☀️ og 🎵.
Ellers må vi jobbe videre ⛏ 🕳 🐇…
Tillegg
En utfordring med Bourne Shell er at det ikke har mange datastrukturer. Man kan ikke returnere en hash-tabell eller et objekt, man må loope over tekstfelter.
Jeg lekte meg med å bygge støtte for --long-option og
kom opp med:
# usage:
# args=$(parselong a/all f/file -- "$@")
# eval "set -- $args"
# while getopts f:a...
parselong() {
c=1
for arg; do
[ "$arg" = "--" ] && break
c=$((c + 1))
done
[ $c -eq 1 ] && return
for arg; do
case "$arg" in
?/*)
short="${arg%/*}"
long="${arg#*/}"
end=
i=0
while [ $((i+=1)) -le $# ]; do
[ "$1" = "--$long" ] && [ -z "$end" ] \
&& o="-$short" \
|| o="$1"
[ "$1" = "--" ] && [ $i -gt $c ] && end=1
set -- "$@" "$o"
shift
done ;;
--) break;;
*) echo "unexpected: $arg"; exit 1;;
esac
done
shift $c
for i; do
quoted=$(printf %s\\n "$i" \
| sed "s/'/'\\\\''/g;1s/^/'/;\$s/\$/'/")
shift
set -- "$@" $quoted
done
echo "$@"
}Nå virker --file foo --all også! Det var ikke trivielt,
men jeg synes det var et lærerikt og morsomt dypdykk i
shell-argumenter 🙂
Send gjerne spørsmål eller kommentarer til Richard Tingstad
openr
Jeg har laget et lite skript som jeg bruker ofte.
Hva?
Det er et skript som åpner en tilfeldig fil i en teksteditor.
Du kan eksplisitt velge teksteditor med
--editor/-e, ellers velger skriptet hva enn du
har i $EDITOR.
Om du bruker vi, vim, nvim,
lvim får du også åpnet fila på en tilfeldig linje.
Om du bruker hx, code, codium
får du også åpnet fila på en tilfeldig kolonne på en tilfeldig
linje.
Hvordan?
function openr
argparse e/editor= -- $argv
or return
if set -ql _flag_editor
set editor $_flag_editor
else
set editor $EDITOR
end
set file (git ls-files | shuf -n1)
set line_text (cat -n $file | shuf -n1)
set line (string sub -l6 $line_text | string trim)
set position (shuf -n1 -i1-(string sub -s6 $line_text | gwc -c))
switch $editor
case hx
$editor $file:$line:$position
case vi vim nvim lvim
$editor $file +$line
case code codium
$editor --goto $file:$line:$position
case '*'
$editor $file
end
endUsage
Man kjører programmet slik:
$ openreventuelt feks slik:
$ openr -e emacseller
$ openr --editor /Applications/Xcode.app/Contents/MacOS/Xcodefish
fish, som dette er skrevet i, er en modernere
sh/bash/zsh. Det er mye bedre å
skrive i, og er ikke POSIX-kompatibelt. Det vil si at du ikke kan
klistre inn vilkårlige shellscripts fra internett og forvente at
fish kan kjøre det. Men det er uansett ikke så lurt.
argparse
argparse e/editor= -- $argv
or returnHer bruker vi fish' finfine argparse-kommando
til å definere og parse kommandoargumenter. Vi sier at vi har
étt argument, editor (kortform: e) som har et
parameter (=), og vi skal lese dette inn fra
$argv (som er en liste over alle ordene man skriver etter
openr).
Denne editor-verdien blir så stappet i de implisitte
variablene $_flag_editor og $_flag_e.
if set -ql _flag_editor
set editor $_flag_editor
else
set editor $EDITOR
endHer sjekker vi om $_flag_editor er oppgitt, og setter
isåfall $editor til den verdien.
Om $_flag_editor ikke er satt setter vi
$editor til å være hva enn $EDITOR er.
Finne frem filer og posisjoner
set file (git ls-files | shuf -n1)Her lister vi ut alle filene git vet om i mappen (og undermapper) man
står i med git ls-files. Så pipes dette inn i
shuf -n1 som gir oss én tilfeldig linje av det som blir
pipet inn, altså et tilfeldig filnavn. Vi setter dette i variablen
$file.
set line_text (cat -n $file | shuf -n1)Her lister vi ut innholdet i fila vi fant i forrige steg. Med
-n får vi også med linjenumre (som vi bruker i et senere
steg.) Så pipes dette inn i en shuf -n1 som over. Så vi
står igjen med $line_text som inneholder en tilfeldig linje
fra fila i $fila, med linjenummer foran.
set line (string sub -l6 $line_text | string trim)Her skraper vi ut de seks første tegnene i $line_text
som vi definerte over, og luker vekk whitespace med
string trim. Vi sitter igjen med linjenummeret fra den
tilfeldige linja i variablen $line.
set position (shuf -n1 -i1-(string sub -s6 $line_text | gwc -c))Denne bråkete linja fjerner linjenummeret fra $line_text
og teller antall tegn med gwc -c. Vi bruker
gwc over wc fordi wc på MacOS
putter inn whitespace før tallet vårt. Så tar vi og generer en
liste av tall fra 1 til det antallet tegn vi nettopp fant.
Så velger vi oss ut et tilfeldig av disse tallene. Og setter det i
$position.
Som du kanskje ser er narrativet i koden og prosaen nokså forskjellig her. Beklager om det er vanskelig å følge, men vi sitter i hvert fall igjen med et tilfeldig kolonnenummer.
switch
switch $editor
case hx
$editor $file:$line:$position
case vi vim nvim lvim
$editor $file +$line
case code codium
$editor --goto $file:$line:$position
case '*'
$editor $file
endHer velger vi hvordan vi vil starte editoren basert på innholdet i
$editor.
- Er editoren vår
hxstarter vi$editor(hx) med en syntaks som spesfiserer linje og kolonne - Er editoren vår en
vi-variant, får vi bare linje - Er editoren vår en
VSCodefår vi både linje og kolonne - Er editoren ukjent får vi bare fila
Hvorfor?
Jeg synes det er nyttig å av og til åpne en tilfeldig fil i et prosjekt og lese den og reflektere litt over hva den gjør/er og hvorfor den eksisterer. Er det en gammel bit med kode? Hvordan passer den inn med den nye koden vi skriver? Ser jeg noen åpenbare forbedringer jeg kan gjøre her og nå? Kanskje denne koden kan hjelpe meg å se resten av koden på en litt annen måte?
Makro-kappløp
Race conditions er kanskje mest omtalt i forbindelse med tråder, men jeg fant en artig en.
På prosjektet har vi mange tjenester, og en veldig nyttig kommunikasjonsform mellom dem, er meldingskøer. Spesifikt bruker vi Kafka-køer. En vanlig egenskap ved meldingskøer er FIFO-oppførsel: First In, First Out. Altså at rekkefølgen til meldingene blir bevart.
Kafka skiller seg fra mange andre meldingskøer ved at køene gjerne deles opp i partisjoner for å få høyere gjennomstrømming.

Hver melding har et innhold, og en key. Denne key’en brukes til å velge partisjon, og innenfor hver partisjon er man garantert FIFO-rekkefølge.
Vi gjorde noe slikt:

Her blir ID (A, B) brukt som
key. Hvis A og B beholder innbyrdes
rekkefølge gjennom hele løypa går alt fint.
Men følgende blir et problem:
B, endret Adresse, fyker gjennom boksene tilBehandling- Leser Ordre
A, Status bestilt
- Leser Ordre
A, endret Ordre, kjører også gjennom løypa og ankommerBehandling- Ordre
A, Status kansellert, sendes videre
- Ordre
- Ordre
Afra punkt 1 blir sendt videre
Vi ender opp med en Status: bestillt etter
“kanselleringen”.
Konklusjon: Ikke anta at meldinger ankommer i gitt rekkefølge gjennom et distribuert system (med ulik key).
Løsninger på det aktuelle problemet kan være:
Behandlingkan sende “Ordre A er endret” i stedet for “Ordre A har fått status X”Bestillingkan alternativt ignorere utdaterte meldinger ved å sammenligne Versjon e.l.
Send gjerne spørsmål eller kommentarer til Richard Tingstad :)
JALS-8
I det siste har jeg jobbet litt med metodene vi bruker for å lage treningsbilder fra satellittbilder i Vake. Vi støtter nå snart fire ulike satellittkilder som alle kommer med litt forskjellig struktur og kompleksitet.
Metodene ble opprinnelig skrevet for den ene satellittkilden vi startet med (Sentinel-2). Denne kilden er ganske kompleks siden “ett” bilde består av 13 bånd (RGB + 10 til) som igjen er strukturert i 4 bildefiler etter den romlige oppløsningen båndene har. Resultatet ble metoder som støtter denne strukturen, men som har blitt veldig komplekse og utfordrende å overføre til nye, mindre komplekse kilder som de jeg holder på med nå, uten at de blir enda mer komplekse og uleselige.
Målet mitt er enklere og ryddigere metoder som støtter alle kildene, og som gjør det enklere å legge til flere kilder i fremtiden. Jeg har begynt å utvikle en lovende løsning basert på arv, men på grunn av den opprinnelige kompleksiteten har dette vært utfordrende og dermed tatt mer tid enn jeg har lyst til å bruke akkurat nå (det er andre mer kritiske ting å gjøre). Det er samtidig digg å fullføre noe man har startet på, kompleksiteten har plaget oss en stund, og det er teknisk/faglig sett en interessant utfordring. På den andre siden har det sneket seg inn en følelse jeg har hatt før, at vi prøver å være smarte og “future-proofe” noe, bare for å innse et halvt år senere at vi ikke visste så mye vi trodde, eller at vi f.eks. finner en pakke som gjør alt mye lettere. Faktisk utforsker Adrian en pakke akkurat nå som kan gjøre mye av det jeg startet på redundant.
Hva er konklusjonen? Jeg vet ikke, men ofte synes jeg vi bruker for mye tid på “future-proofing” eller optimalisering av metoder basert på hypoteser om fremtidig bruk. Men ofte har det også blitt motbevist, som har gjort at vi raskt og effektivt kan levere på nye muligheter som oppstår.
JALS-7
Jeg jobber nå med refactorering (igjen). Målet er å fjerne kompleksitet og øke fleksibilitet i en flyt. Denne flyten kan beskrives som: hvordan lese et satellittbilde for:
- trening (ML)
- prediksjon i prod (inference)
Bildene er veldig store, og passer ikke i minnet (“CPU-” eller GPU-minne), så vi chunker opp bildet i mindre vinduer. Kan sammenlignes med convolution, “bare ett lag ut”.

Se for dere at proposjonene er 10.000 x 10.000 for satellittbilde (blå rute) og 512 X 512 for hver chunk (vindu vi laster inn i minnet om gangen). Som i gif’en vil vi også la hver chunk overlappe med den forrige med feks. 50 pixler.
Jeg fant et relativt nytt bibliotek TorchGeo som kan erstatte mye av den kompliserte koden. Denne har vi en del krav til for at den skal kunne støtte vår bruk.
- Den må ikke være tregere enn den eksisterende løsningen
- Den må ikke stille strenge krav til oss på feks formater eller fil-struktur
- Det må være enkelt å tweake den
- … jeg kommer på fler og fler
Jeg gjorde noe de-risking ved å én-til-én teste med den eksisterende koden og fant fort ut at den kom til kort på ett punkt. Den kan ikke lese bilder direkte fra en cloud bucket, slik som vår kode kan.
Her har heller ikke kildekoden lagt opp til at man kan tweake den så
lett. Jeg må override hele init-metoden kun for å fjerne en
sjekk på om filen eksisterer. Selve lese-metoden klarer fint å lese fra
bucket, men sjekken gjør ikke.
Da har jeg to alternativer:
- Overskrive
init - Lage en PR til biblioteket
I nummer 1. vil jo min implementasjon overskrive resten av logikken i
init for alltid, og fremtidige oppdateringer i kildekoden
går tapt.
Det riktige er helt sikkert nummer 2. med en fiks som løser problemet for alle andre brukere av bibliotek. Men det tar tid, og jeg må gjøre det skikkelig og sette meg inn i nye ting jeg ikke kan. Samtidig så har jeg jo en stor gjeld til open-source-miljøet. Samtidig har jeg ikke fått de-risket biblioteket fullt ut enda. Jeg tror jeg må gå for 2 likevel, må jeg ikke?
OLORM-26: Unix på godt og vondt
Da jeg skrev første versjon av
olorm-kommandolinjeprogrammet, ble jeg superengasjert da
jeg fant ut at jeg kunne bruke miljøvariabelen EDITOR.
git bruker EDITOR til å la brukeren styre
hvilket program brukeren ønsker å redigere Git-commit-meldinger med.
Hvis du vil skrive commit-melding med Vim, kan du kjøre
EDITOR=vim git commit. EDITOR=emacsclient -nt
gir deg en Emacs-instans i terminalen, og EDITOR=code -w
gir deg Visual Studio Code.
Adrian skrev til og med en shell-funksjon så han fikk det som han
ville, og kunne skrive j i stedet for
EDITOR="open -a blablabal" jals create. Nå finner jeg ikke
koden, men jeg mener å huske at han gjorde noe sånt:
# i ~/.zshrc
j() {
EDITOR="open -a markdownedit -w" olorm create
}Så Adrian kunne få til det han ville helt på egen hånd! Det synes jeg er dritkult, vi får i tillegg løftet opp hva Unix/Posix egentlig er.
På den andre siden:
- Vi har støtt på uforutsette problemer /hver gang/ nye personer har installert CLI-et.
- CLI-et har tilgang til mappesystemet, som gjør at vi åpner for at folk som skriver OLORM og JALS kan bli utsatt hvis jeg (Teodor) blir utsatt for angrep via avhengigheter.
- Mange folk bruker ikke terminalen. Det hadde vært dritgøy å få designere, produktledere og andre til å skrive.
Men! Jeg mener fremdeles vi har tatt gode valg.
- Vi har shippet
- Og vi har gjort det på en måte som har fått de som har skrevet til å fortsette å skrive.
“Funker ikke perfekt for alle helt ennå” kan vi løse i fremtiden, hvis vi velger å fokusere på det.
OLORM-25: Markdown-lenker på tre forskjellige måter
Markdown støtter å lage lenker. Men du kan lage lenker på forskjellige måter! Her er tre alternativer.
Metode 1: Inline-lenker:
Markdown:
[teodor](https://teod.eu)HTML:
Metode 2: Referanse-lenker med valgt navn:
[teodor][1]
[1]: https://teod.euHTML:
Metode 3: Referanse-lenker med implisitt navn.
Markdown:
[teodor]
[teodor]: https://teod.euHTML:
Av de tre, foretrekker jeg referanse-lenker med implisitt navn.
- Det er minst kode
- Det innfører færrest antall nye navn i koden. Med andre ord, det minimerer mengden abstraksjon.
- Det utfordrer meg til å gi lenken min et godt navn.
- Det blir minimalt med visuell støy rundt lenken. Gigantiske lenker
midt inni et avsnitt, som
[til en fil](https://github.com/iterate/olorm/tree/65be6088ae2b54b4b7e9413acaed8327d220ec84/serve/src/olorm/devui.clj)gjør at avsnittet blir vanskelig å lese når man leser plaintext.
Såvidt jeg vet støttes alle tre i Github Flavored Markdown og i CommonMark. Jeg foretrekker å bruke Pandoc til å jobbe med Markdown, og Pandoc støtter CommonMark. Her i Mikrobloggeriet bruker vi Pandoc til å konvertere Markdown til HTML.
—Teodor
JALS-6 - Lage en editor i browseren
Jeg jobber med å lage en editor Unicad for ren tekst (uten formatering). Men vi ønsker å lagre informasjon om hva brukeren gjør, ikke kun enderesultatet.
Dvs, istedet for å lagre teksten hei, vil vi lagre det
brukeren gjorde for å komme dit. Om brukeren skriver hi,
ser brukeren har gjort en feil, visker vekk i og skriver
ei så det blir hei, vil vi lagre:
- Skrev
hpå posisjon 0 - Skrev
ipå posisjon 1 - Visket ut posisjon 1
- Skrev
epå posisjon 1 - Skrev
ipå posisjon 2
Dette for å få til collaborative editing, og for effektivt kontinuerlig kunne sende meldinger frem og tilbake til serveren.
Det finnes en løsning for dette, og det er et event som heter
beforeInput. Det er er en event som skjer rett etter
brukeren har gjort en handling, men før handlingen “får effekt” i
DOM-en. Her kan vi både se hva brukeren gjør, og også stoppe handlingen.
Dette er det vi bruker for rik-tekst i Unicad.
Denne eventen støttes av <textarea>. Så alt ser
bra ut. Trodde jeg. Helt til jeg fant ut at når man kobler dette på en
<textarea> så fungerer ikke
getTargetRanges(), som er en funksjon som returnerer
hvor endringen skjedde. Det hjelper ikke om vi vet at brukeren
skrev i hvis vi ikke vet hvor i-en skal
være.
Vi kan trikse oss rundt det ved å bruke <textarea>
sin selectionStart og selectionEnd. Men disse
returnerer hvor selection er nå (dvs før hendelsen skjedde,
siden DOM-en ikke er oppdatert enda), ikke hvor endringen kommer til å
skje.
Om brukeren trykker Ctrl+Backspace vil man i de fleste browsere viske
ut et helt ord. Men for å støtte denne med beforeInput i et
textarea må vi faktisk selv finne ut hvilket ord brukeren
har visket ut, vi får kun vite at brukeren har gjort input action
deleteWordBackward, og hvor cursoren stod når brukeren
gjorde det.
Det er også flere ting som gjorde koden vanskelig å ha med å gjøre
når jeg brukte textarea og beforeInput.
Resultatet var at jeg måtte endre til en <div> med
content-editable=true som har sine egne quirks, blant annet
dårligere støtte for universell utforming.
Så konklusjonen er: Editering i browseren er broken (men ikke så
broken som før vi fikk beforeInput, som var så sent som
2021). Skal du lage en editor i browseren, bruk et tredjepartsbibliotek
som CodeMirror (for ren tekst) eller ProseMirror (for rik tekst). Det er
en grunn til hvorfor vi velger å ikke gjøre det i Unicad, selv om vi på
ingen måte er sikre på at vi tok riktig valg (men fremdeles heller mot
at vi gjorde det riktige valget). Hvorfor vi ikke bruker CodeMirror og
ProseMirror i Unicad får være en annen jals.
Har du spørsmål eller kommentarer, ta kontakt med meg på slack (for Iterate-ansatte) eller på mail (for andre).
– Sindre
JALS-5: Mange veier til Rom
Som en programmerer både hater jeg og setter pris på på hvordan det samme resultatet kan oppnås på forskjellige måter. Ta for eksempel følgende react-komponenter.
const PermissionCell = ({
permission,
}: {
permission: LibraryPermissionType;
}) => {
const t = useT();
return (
<div>
{(() => {
switch (permission.scope) {
case 'owner':
return t('Administrator');
case 'write':
return t('Can edit content');
case 'read':
return t('Can use content');
}
})()}
</div>
);
};export const PermissionCell = ({
permission,
}: {
permission: LibraryPermissionType;
}) => {
const t = useT();
return (
<div>
{permission.scope === 'owner' && t('Administrator')}
{permission.scope === 'write' && t('Can edit content')}
{permission.scope === 'read' && t('Can use content')}
</div>
);
};De utfører alle samme oppgave, men på forskjellige måter. Dette spekteret av muligheter kan noen ganger gjøre koding utfordrende. Likevel gir det også rom for kreativitet og tilpasning. Og mens noen kanskje vil diskutere hvilken metode som er “best”, synes jeg ikke det spiller noen rolle så lenge koden fungerer som den skal og sjeldnere og sjeldnere gidder jeg å ha en mening i pr-reviews så lenge jeg skjønner hva som skjer.
Det viktigste for meg er at neste utvikler som leser koden forstår hva som skjer. Og det er denne balansen mellom funksjonalitet og forståelighet som er det sanne målet god kode. Som med så mye annet i livet, er det mange veier til samme mål.
(Skrevet 96% av chat gpt)
Refactoring is dead
La oss slutte å snakke om refactoring.
Her er en uutfyllende liste over hva man kan mene når man sier refactoring:
Refactoring is a disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behavior. [Refactoring.com]
- Å utføre en av de navngitte refactoringsene i Refactoring-boka [MartinFowler]
- Å gjøre en “trygg” automatisk kodeendring/code action i feks IntelliJ
- Å gjøre en vilkårlig automatisk kodeendring i feks IntelliJ
- Å gjøre en manuell “trygg” kodeendring
- Å endre kode uten å brekke tester
- Å rydde i kode
- Fikse linterfeil
- Skrive flere tester
- Optimalisere kode til å kjøre raskere
- Koding som ikke er dekket av en JIRA task
- Koding (hva som helst)
Så selv om du kanskje vet hva du mener når du sier refactoring er sjansen stor for at den som hører/leser ikke vet hva du mener. Kanskje de erstatter din oppfattelse med sin egen. Eller kanskje de, kloke av skade, erstatter med sin egen og legger til et buffer av vaghet og godvilje.
Når du sier refactoring er det sansynlig at mottaker sitter igjen med mindre informasjon enn du mente å gi.
Det er kjedelig å miste informasjon. Men jeg synes det er et større tap at hver gang du sier refactoring kunne du sagt noe annet som er mer eksplisitt og mer beskrivende. Hvor interessant er det egentlig om endringen din er en refactoring eller ikke? Kan du ikke heller si hva du gjorde?
- Erstattet en klump string literals med en Enum-type
- Dro parse-logikken ut i et eget modul
- Sorterte funksjonene så det er lettere å lese dem fra toppen og ned
- Inverterte noen nesta ifs så vi kan gjøre en earligere early return
JALS-4: Vi rakk det
JALS intromøte. Det er satt av 50 minutter. Jeg liker ikke møter som er lengre enn 30 minutter fordi jeg ikke klarer å holde fokus så lenge. Folk flest klarer ikke det. Jeg opplever også at det sjelden er en møte-agenda som krever mer enn 30 minutter, man bare setter av ekstra tid i tilfelle. Dette fører veldig ofte til at man bruker 10 minutter bare på å komme gang med møtet. Så bruker man 20 minutter på første møtepunkt fordi man tenker man har god tid, før man innser at man har 4 møtepunkter igjen på de siste 20 minuttene. De 4 viktigste. I utgangspunktet hadde 20 minutter holdt til de 4 punktene, men nå har det jo gått 30 minutter og lufta er ute av ballongen. Jeg har brukt mine tilmålte 30 minutter konsentrasjon på møtejazzing. Jeg går på tomgang, og for hvert minutt som går vil det kreve 2 minutter ekstra etter møtet for å få hodet i balanse igjen.
Adrian kom inn i møtet med en tidsfrist på 15 minutter. Et uforutsett styremøte i Vake. Vi kom oss igjennom agendaen.
Generell find & replace
Search & replace av tekst i filer er kjekt med
sed -i (in-place):
find . -name \*.txt -exec sed -i.bak 's/foo/bar/g' {} \;Men det er ofte kommandoer ikke har et in-place-flagg. Da
kan man kjøre (eksemplifisert med jq .):
find . -name \*.json -exec sh -c 'jq . {} >tmp && mv tmp {}' \;Send gjerne spørsmål eller kommentarer til Richard Tingstad :)
JALS-3
Jeg syns det var passende at min første JALS kunne handle om
installasjon av jals/olorm cli siden jeg hadde fått en liten advarsel om
at noe kunne mangle i README-en, og jeg lærte litt av
prosessen.
For å installere fulgte jeg stegene for å klone repo-et, installere
babashka og bbin og eventuelt legge til noe på
PATH uten problemer. Da jeg skulle installere
jals derimot, ble jeg møtt av en error som etter litt om og
men tydet på problemer med Java-installasjonen min. Siden
jals er skrevet i Clojure som er koblet til Java, ga det
litt mening.
Hva var problemet med Java-installasjonen? Den fantes ikke. Java JDK
blir ikke (lenger?) forhåndsinstallert på Mac, og jeg har aldri hatt
bruk for det. Det er flere måter å installere Java JDK på Mac, men den
enkleste for meg syntes å være via brew.
Jeg kjørte brew install java som installerer Java under
/opt/homebrew/, men det i seg selv er ikke nok da systemet
leter etter Java JDK under
/Library/Java/JavaVirtualMachines/. For å løse dette kan
man bruke symlinks (symbolic links), som er en fil som har som formål å
peke på en annen fil eller mappe. Ved å lage en sånn link i systemets
mappe for JVMs (/Library/Java/JavaVirtualMachines/) vil
systemet automatisk finne Java uten at man trenger å f.eks. gjøre noe
med PATH. Symlinks kan lages med kommandoen
ln -s på kommandolinjen:

Som man ser på bildet, kjørte jeg ln kommandoen og en
link/fil dukket opp i mappa. Det gjorde at systemet fant Java, og da
gikk installasjonen av jals smertefritt!
En fin dag med Elm
I går hadde jeg en veldig fin dag med Elm programmering, og det er ganske lenge siden sist jeg satt meg ned og lagde noe nytt i Elm. Alle nye frontender vi lager har blitt React/TypeScript, først og fremst for å enklere komme tettere på browseren i noen tilfeller og bibliotekstøtte i andre, sekundert er også bekjentskapen til Elm på teamet en faktor.
En Elm modul består av et view, en modell og en update funksjon for å gjøre endringer på modellen. I tillegg har man en init funksjon for å sette opp modellen, ofte med data fra backend. Vi har en rekke forskjellige måter å bestille strikkeplagg på, det kan være uten annen input enn ditt eget hode, et produkt vi har laget i Sanity, en digital strikkeoppskrift eller nå snart, ditt eget design i en 3D-modell.
For hver av de forskjellige måtene å bestille på henter vi data fra forskjellige steder. I browseren får forskjellige url-er. Modellen og viewet er helt likt i alle tilfeller, men hver url leder til forskjellige init-funksjoner som henter data fra riktig kilde. Det blir veldig oversiktlig og enkelt. For hver init funkson trenger vi også ett innslag i update-funksjonen som setter dataen inn i modellen.
Filtrering av grupper av innslag
På prosjektet har vi en relasjonsdatabase med en ganske stor tabell med over 30 millioner rader. Innslagene inneholder tidspunkt med “item”s status med mer. Ca slik:
+----------+---------+------------+---------+----
| id | item_id | version_id | state | ...
+----------+---------+------------+---------+----
| 45649802 | 11111 | 1 | A |
| 45649811 | 11111 | 2 | B |
| 45649817 | 12222 | 2 | C |Vi oppdaget at noen status-innslag manglet, og trengte å hente ut
alle disses item_id. Vi ville finne alle som har state
B, men ikke har hatt state A. Jeg liker
HAVING SUM(CASE for slike spørringer:
SELECT item_id
FROM history
GROUP BY item_id
HAVING SUM(CASE WHEN state = 'A' THEN 1 ELSE 0 END) = 0
AND SUM(CASE WHEN state = 'B' THEN 1 ELSE 0 END) > 0Men når rekkefølge teller, liker jeg
LEFT JOIN WHERE NULL:
SELECT t1.item_id
FROM history t1
LEFT JOIN history t2
ON t2.item_id = t1.item_id
AND t2.version_id > t1.version_id
LEFT JOIN history t0
ON t0.item_id = t1.item_id
AND t0.version_id < t1.version_id
AND t0.state = 'A'
WHERE t1.state = 'B'
AND t0.item_id IS NULL
AND t2.item_id IS NULL ;Denne sier to ting:
- At
Ber siste status (t2med nyere rad finnes ikke;IS NULL). - At ingen tidligere rad med status
Afinnes (t0).
Hvis dette feiler (SQL’en tar for lang tid), kan man velge å frigjøre seg fra databasen:
mysqldump -u USER -p \
--single-transaction --quick --lock-tables=false \
DATABASE history > hist.sql
grep INSERT hist.sql | tr \( \\n | grep , > hist.csv
sort -s -t , -k 2 -k 3 hist.csv > sorted.csvDe første kommandoene her tar noen minutter. sort bruker
lenger tid på store filer, men er veldig robust.
< sorted.csv awk -F "'?,'?" '{
if ($2 != prev) {
if (match(states, "B$") && !match(states, ",A,"))
print prev
states = ""
}
states = states "," $4
prev = $2 }' > itemIDs.txt For hver item_id ($2 = kolonne 2): print
hvis siste state var B og ingen tidligere state
A fantes.
Konkusjon
Det er sikkert mange mulige måter å løse denne oppgaven på, dette var én måte.
For meg virket LEFT JOIN-teknikken bra, og jeg synes de
deklarative SQL-spørringene er enklere å lese og forstå enn den mer
imperative AWK-koden.
Jeg liker dog at man har muligheten til å løse (og dobbeltsjekke) oppgaven på flere måter.
Send gjerne spørsmål eller kommentarer til Richard Tingstad :)
JALS-2: Salg i Unicad
Jeg har akkurat vært i møte med en potensiell kunde for Unicad, startupen hvor jeg er CTO (og en av to foundere) Som utvikler er det ikke veldig vanlig å være i direktekontakt med kunder, men for meg er et slikt møte verdifullt.
Jeg får feedback til hva kundene synes gir verdi, og det er viktig å vite når man lager et produkt. Spesielt når man er i tidlig fase slik som oss.
Jeg blir inspirert ved å vite at det jeg lager blir brukt av ekte mennesker som løser ekte problemer.
Og ikke minst gir det muligheten for teamet ha en god samtale om hva vi synes er verdi og hva vi vil prioritere videre. Har vi de samme tankene etter møtet, eller sitter vi igjen med forskjellig inntrykk? Uansett om vi er enige eller uenige så gir det oss verdifull innsikt.
For et lite startup-team på to personer så er det kanskje ikke så uvanlig at den som er CTO er med i salgsmøter, men kanskje man burde innføre det også for større selskaper. Hvordan skal vi videreføre denne verdien når vi vokser og er så store at vi har egne selgere?
Frontend og backend
Det vi lager deler vi ofte opp i en frontend og backend og mye er åpenbart om skal plasseres i frontend eller backend, men noen ting er ikke like rett frem.
Med moderne frontendrammeverk blir det lettere og lettere å skrive mer og mer av logikken til applikasjonen i frontenden, men en del ting vil være mer effektivt å plassere så nærme databasen som mulig. Og det blir kanskje spesielt tydelig etterhvert som applikasjonen vokser.
En ting jeg ser flere ganger når jeg utvikler endepunkter i backenden vår er at frontend-utvikler i litt for stor grad godtar at det de får av data fra backenden ikke er optimalt. Om man må gjøre først en request og så 5 til, bør man heller ta en runde til med utforming av API-et så man får akkurat det man trenger i frontenden.
Når jeg utvikler både frontend og backend selv blir det ofte at jeg begynner med backenden, så prøver å løse frontendproblemet og så går noen runder frem og tilbake til jeg finner den optimale løsningen. Men så er også en av mine svake sider at jeg ikke er så flink til å planlegge godt på forhånd.
JALS-1
Jeg refaktorerer hvordan vi håndterer trente maskinlæringsmodeller. Vi bruker et verktøy kalt neptune som, etter en trening, lagrer vektene i sin sky. Vektene til en modell representerer det modellen har lært. Når vi skal kjøre inference på ny data (bilder), må vi laste ned disse vektene igjen for å instansiere modellen.
Problembeskrivelse:
- Under trening lagres vektene lokalt i en mappestruktur som neptune velger selv, før den lastes opp til sky.
- Vi ønsker å bruke den samme mappestrukturen når vi laster ned vektene igjen. Følge standarder
- Når vi skal kjøre inference forholder vi oss kun til en “modell-id”, og vet ikke denne mappestrukturen.
- Vi kan gjøre kall mot neptune for å få denne mappestrukturen.
- For “viktige” modeller/vekter ønsker vi å cache vektene i vår egen bucket, slik at vi ikke er avhengig av neptune i produksjon.
Hovedproblem:
Hvordan gjenskape mappestrukturen uten å gjøre kall til neptune, og uten å hardkode masse greier?
Dette er et kjedelig problem som jeg ikke finner mye kvalitet i. Jeg tror det er grunnet i en forventning om at verktøyet (neptune) burde håndtere dette annerledes, eller tilby mer fleksibilitet enn det gjør.
Å isolere feil når du ikke har tid til å fikse dem
Om du eller noen andre finner en feil oppførsel i et dataprogram du jobber med er det vanlig at første steg videre er å reprodusere feilen.
Er feilrapporten god nok og du har god nok innsikt i koden din, kan det være at du kan reprodusere feilen direkte i en eksempeltest. Det er et ypperlig utgangspunkt for å fikse feilen.
Men av og til er jobben det vil ta å fikse feilen så stor at du ikke har tid til å gjøre det. Ellers kan det hende at feilen ikke er grov nok til at du prioriterer å fikse den over andre ting du vil gjøre.
Du vil gjerne ikke la feilende tester ligge å slenge i kodebasen din, så da sletter du den og lager kanskje en GitHub issue eller skriver om feilen på en post-it.
Men om du er kul og lur, beholder du testen din. I stedet for at den tester at ting går bra, får du den til å teste at feilen produserer en god og unik feilmelding.
I testen kan du kanskje skrive en kommentar om at du ikke prioriterer å fikse feilen her og nå.
Om du bruker Sentry eller noe lignende, kan du nå spore og følge med på feilen. Du kan referere til den og snakke og tenke om den.
Jeg synes dette er bedre enn å ignorere feilen til du får tid/lyst til å fikse den.
Go chans & Unix pipes
Jeg har lagt merke til likheten mellom Go channels og Unix (named) pipes.
Go’s approach to concurrency […] can also be seen as a type-safe generalization of Unix pipes.
Først, hva er named pipes igjen?
command | grep fooer en “vanlig” pipe og kan ses på som en spesialisering av en named pipe:
mkfifo mypipe
command > mypipe &
<mypipe grep foo
rm mypipeSelv om det opprettes et filnavn, vil ikke data skrives til fila. Named pipes gir mye mer fleksibilitet for sending og lesing av meldinger enn en navnløs pipeline.
A Tour of Go - Concurrency introduserer channels med kode som summerer tall med to goroutines. Sammenlign med min implementasjon i UNIX shell:
#!/bin/bash
set -e
sum() { c=$1; shift
sum=0
for v in $@; do
sum=$(( sum + v ))
done
echo $sum > $c # send sum to c
}
main() {
s=(7 2 8 -9 4 0)
c=/tmp/chan$$ guard=/tmp/pipeguard$$
mkfifo $c
mkfifo $guard; >$c <$guard &
n=$[ ${#s[@]} / 2 ]
sum $c ${s[@]:0:n} &
sum $c ${s[@]:n} &
{ read x; read y; } <$c # receive from c
echo $x $y $((x+y))
>$guard; wait
}
mainJeg synes koden er veldig lik. mkfifo $FILNAVN tilsvarer
navn := make(chan t).
$guard opprettes som en (inaktiv) skriver til
$c for at den ikke skal lukkes for tidlig. FIFOer (named
pipes) lukkes når alle skrivere er lukket (ferdige).
sum $c ${s[@]:0:n} & tilsvarer selvsagt
go sum(s[:len(s)/2], c). & starter en
asynkron prosess, lignende som go. Shell angir som kjent
argumenter som ord, uten paranteser og komma. Slice’en sendes som et
slags variadic argument, så det er mest praktisk å ha c som
første parameter. (Håndteringen av array i main() er forøvrig eneste
Bash-isme i koden.)
Den siste linja i main() er bare høfflig opprydding som
lukker FIFOene og avventer at alle prosessene er avsluttet.
Send gjerne spørsmål eller kommentarer til Richard Tingstad :)
Godt håndtverk
Jeg har akkurat funnet en skikkelig god elektriker. En som er nøye, men effektiv, passer på at det ser bra ut etterpå og at ting er logisk lagt opp (innerste lysbryter skrur av det innerste lyset). Han sa også, “jeg bruker litt ekstra tid på dette og så blir det mye enklere for neste elektriker som kommer” - og det vil fra nå være han selv. Tidligere elektrikere har resultert i synlige gule betongplugger og borring av for store hull med påfølgende akrylmasse.
Etter det kom jeg til å tenke på min egen jobb og jeg fikk fornyet motivasjon til å forsøke å utføre et godt håndtverk. Jeg mener forøvrig at godt håndtverk ikke bare gjelder for det vi kaller håndtverkere og programmerere, men også om du f. eks skriver et strategidokument eller lager et regneark.
Så, hva er det jeg prøver å gjøre? Hovedsakelig gjelder det å etterlate koden lik, eller litt bedre, enn den var når man kom dit så det vil være lettere for neste mann, som antakeligvis er meg selv.
Det gjør også at det er lettere å ta de snarveiene man noen ganger må ta for å få ting ut når det noen ganger haster.
Fart i utvikling?
Utviklingsfart er noe det ofte fokuseres på, men som jeg synes er vanskelig.
Jeg har ikke møtt noen som mener at flest antall kodelinjer per time er en god metrikk for produktivitet.
Likevel føler jeg litt den samme tilnærmingen med antall “saker” løst.
Dette kan jeg også føle på indirekte i standup-runden med spørsmålet “hva har du gjort i dag/går?”
Avhengig av hva man jobber med er det lett å føle at “Mari & Per er mye mer produktive enn meg, de shipper jo saker i ett kjør”.
Selvfølgelig gjelder jo fortsatt kvalitet > kvantitet. (Jeg tar meg i å stadig oftere helle i retningen av at all ny kode er en “byrde”, det er viktigere at du skriver den riktige koden, enn at du skriver kode.) Apropos: I fysikk skiller man mellom fart og hastighet, der sistnevnte har retning. Høy utviklingsfart er ikke alt :)
Men tilbake til Mari & Per. Jeg hørte nylig en podcast der en forfatter nevnte at det er teamets fart som er interessant. Hvert individs fart er ganske irrelavant. Så hvis du bruker en hel eller halv dag på å gjøre en skikkelig god code review, eller å lære opp en kollega i noe nytt, så er det kjempenyttig for teamets funksjon som helhet.
Ikke veldig ny kunnskap dette, men en fin påminnelse når man i standup føler man “bare” har gjort “admin”-ting den siste tiden :)
Send gjerne spørsmål eller kommentarer til Richard Tingstad :)
Zooming
De siste dagene har jeg tenkt litt på hvordan jeg bruker zooming i programmering.
–
Jeg liker å skrive tester før jeg skriver implementasjon. Av og til merker jeg en slags ubalanse hvor feks testene jeg skriver ikke henger så godt sammen med implementeringen. Eller at implementeringen er vanskelig. Da har jeg lært meg til å se etter et “mindre” problem å løse ved å enten zoome inn eller zoome ut.
Zoom ut
Jeg kan prøve meg på et tenkt eksempel:
Se for deg at du vil lage en funksjon som tar inn en liste med tall, og returnere en ny liste som er som input-listen—men alle tallene er lagt sammen med tallet til venstre for seg selv ganget med tallet til høyre for seg selv. Se for deg at du skriver litt eksempeltester, og det går greit til å begynne med, men etter hvert som eksemplene blir mer kompliserte blir implementasjonen vanskeligere. Helt til du innser at inni implementasjonen din ligger det en litt ræva reduce-implementasjon. (Her later vi som programmeringsspråket ditt ikke har noen reduce fra før.) Nice! Da kan du zoome ut.
Lag en ny fil/modul/klasse hvor du skriver tester for og implementerer reduce-en din uten støyen fra de obskure detaljene i den originale oppgaven din. Når du er fornøyd (nok), kan du zoome inn igjen og fortsette på den originale oppgaven.
Zoom inn
Flippen er at du kanskje så at “legge sammen med et tall og gange med et annet tall” er én ting du gjør mange ganger i problemet ditt. Så hva er enklere enn å gjøre én greie med mange ting? Det er å gjøre én greie med én ting! Så da kan vi zoome inn og lage en ny funksjon feks, som legger sammen et tall med et annet tall ganger det med et tredje tall. Zoom ut til originalproblemet ditt når du er ferdig.
Byggetid og utviklingsmiljø
Hvor mye har byggetiden til utviklingsmiljøet å si for produktiviteten?
Vi har en backend i Rust som etterhvert har blitt ganske treg til å bygge - også loopen som kjører fra man har skrevet kode til man får eventuelle feilmedlinger går også for sakte. Rust er kjent for å være raskt når det først er bygget, men kan bruke til gjengjeld ganske lang tid å bygge.
Det som gjør at man fort blir sittende med lang byggetid er at det kan være ganske krevende å finne ut av akkurat hva som gjør at ting tar tid. Er det et bibliotek man bruker eller er det noe man selv har gjort som kunne vært optimalisert?
Uansett, det værste med at byggetiden trekker ut er at man kommer at av flowen man ofte har når man får konsentrert seg om en utviklingsoppgave.
Også det å skulle kjøre for eksempel TCR vil være helt umulig.
AWK detaljert detalj
Det er overraskende vanskelig å finne nedlasting-størrelsen av et
Docker-image, men noen skrev at man kan bruke
manifest inspect:
docker manifest inspect -v $image | awk '/"size":/{s+=$2}END{print s/1024/1024 " MiB"}'Her avhenger jeg av at "size": 123 er på hver sin linje,
noe som ikke er urimelig.
Men jeg ble også nysgjerrig på: her summeres 123, uten
problemer. Hvor trygt er det? Til og med dette virker:
echo "1432kroner" | awk '{ print int($1/100) " hundrelapper" }'
14 hundrelapperSpesifikasjonen
har noen kompliserte regler for om feltverdien tolkes som tekst, tall
eller numeric string. Det viser seg at det ikke er så viktig,
fordi +-operatoren alltid er Numeric, og:
the value of an expression shall be implicitly converted to the type needed for the context in which it is used. A string value shall be converted to a numeric value either by the equivalent of the following calls to functions defined by the ISO C standard:
setlocale(LC_NUMERIC, ““); numeric_value = atof(string_value);
Funksjonen atof er spesifisert som:
The call atof(str) shall be equivalent to: strtod(str,(char **)NULL),
og strod:
decompose the input string into three parts:
An initial, possibly empty, sequence of white-space characters (as specified by isspace())
A subject sequence interpreted as a floating-point constant or representing infinity or NaN
A final string of one or more unrecognized characters, including the terminating NUL character of the input string
Then they shall attempt to convert the subject sequence to a floating-point number, and return the result.
Å lese spec’en er tidvis tungt siden det er så tett knyttet til C-koden.
Men vi kan konkludere: Det er trygt å anta at alle ukjente tegn etter tallet blir ignorert :-)
P.S. Du vil kanskje filtrere docker manifest på
platform.architecture.
Send gjerne spørsmål eller kommentarer til Richard Tingstad :)
JSON i Postgres
Jeg bruker mye JSON (egentlig JSONB som er mer effektivt) i Postgres og det er både raskt og enkelt å endre, men må brukes med måte.
Når vi laget designverktøyet vårt gikk i utgangspunktet alt av data fra frontenden og rett gjennom backenden som JSON og inn i en tabell i postgres. Det fungerte overraskende bra og gjorde at utviklingen av frontenden ikke trengte å stoppe opp på grunn av backend-oppgaver. Det gjorde frontend (JS/React) utviklerne mer autonome uten at de trengte å lære seg alt av backenden (Rust).
Etterhvert, når man begynner å få litt data som ikke bare kan slettes kan man begynne å savne gode gamle database-skjemaer, spesielt når det gjelder database-migreringer er det godt å kunne lene seg på noen skjemaer.
Som nevnt har vi Rust som backend og den bestemmer hva som får komme i JSON-kolonnene og ikke, det fungerer veldig bra sammen med sqlx som vi bruker til å gjøre spørringer mot databasen. For å skrive JSON til databasen må det ha en egen struct:
struct Image {
name: String,
alt: Option<String>,
}og spørringen blir derfor
let image = Image {name: "123", alt: None };
let yarn_id = 1;
sqlx::query!(r#"
UPDATE yarn
SET image = $1
WHERE id = $2
"#,
sqlx::types::Json(image) as _,
yarn_id
)
.execute(db)
.await?;Her må vi wrappe image i en Json type fra sqlx.
For å hente data ut gjør jeg
struct YarnQuery {
image: sqlx::types::Json<Image>
}
sqlx::query_as!(r#"
SELECT image as "image: sqlx::types::Json<Image>"
FROM yarn
WHERE id = $1
"#, yarn_id)
.fetch_one(db)
.await?;
Vi ser at sqlx trenger litt hjelp for å vite hvilke type det er når
vi setter inn JSON i as.
Når det gjelder performance så har postgres støtte for å lage indekser på verdier inne i en JSON-kolonne, uten at vi har hatt bruk for det enda.
Objektiv trynefaktor
Jeg leste nylig halve Mark Seemans bloggpost, Are pull requests bad because they originate from open-source development?.
Jeg antar at den siste halvdelen er argumentasjon for hvorfor det kanskje ikke stemmer at pull requests er bad fordi de kommer open-source-utvikling. Men som sagt har jeg bare lest halve.
I første halvdelen gjør Mark sitt ytterste for å stålmanne argumentasjonen han argumenterer mot. Først ved å prøve å gjengi originalargumentet så nyansert som mulig. (Denne teksten handler ikke om det.) Så ved å flagge sin egen predisposisjon og forutinntattheter. (Denne teksten handler om det.)
Mark forteller om hvordan han fortrekker pull requests over parprogrammering eller gruppeprogrammering. Han anser seg selv som introvert og mostly prefer solo activities. Han forteller om hvordan han foretrekker å jobbe hjemmefra, hvor han får plenty anledning til dyp fokus. Til forskjell fra å jobbe på et bråkete kontor, med lang pendleavstand. Han føler han får stort utbytte av fleksibiliteten han får av å jobbe ansynkront.
Der stoppet jeg å lese fordi jeg begynte å tenke.
Hvor mange av mine “profesjonelle” meninger om hva som er bra og hva som er dårlig er egentlig personlige preferanser? Det er sikkert ikke så vanskelig å selektivt velge seg overbevisende argumenter for hva enn preferanser man helst så at var sanne.
Jeg er dårlig til å fullføre ting, så for meg er det veldig nyttig å bryte oppgaver ned i veldig små steg, som alle gir litt og litt verdi. Det er en slags personlig work-around for min personlighetstype — men også et råd jeg gir andre i øst og vest med en slags implikasjon om at det i de fleste tilfeller er bedre enn å ta større steg. Min personlige preferanser stemmer nokså godt med hva som er ansett som god praksis av toneangivende stemmer i min boble.
Men det kan jo være at de i min boble bare har samme personlighetstype som meg. Og at de gode almenne rådene deres egentlig bare er ting som har fungert for dem. Også har de kanskje korrelerende personlighetstrekk som gjør at de ender opp som toneangivende.
Det kan også være at min boble også er et resultat av selektivitet. At jeg har endt opp i min boble ved å lytte til folk som sier ting jeg allerede er enig i. At det finnes konkurrerende, like gyldig bobler for en hver personlighet.
Hvem vet? Jeg tror i hvert fall ikke at min “jeg blir mindre distrahert av å jobbe sammen med noen” har en moralsk upper hand over “jeg er mer fokusert når jeg jobber alene”.
Go slice size bug og søk
Jeg innførte nylig en bug i prod:
parentIDs := make([]string, len(parents.els))
for _, el := range parents.els {
parentIDs = append(parentIDs, el.Id)
}Den første linja skulle hatt
make([]string, 0, len(parents.els)), slik at
kapasiteten blir satt til det siste argumentet, men
lengden blir satt til 0. Dette fordi append legger
til elementer på slutten av slice-en.
Jeg gjorde så et søk i kodebasen etter flere tilfeller:
find . -name \*.go -exec \
awk '/= make\(\[\][^,]*,[^,]*$/ { # linjer med "= make([]" og ett komma
if ($1 == "var") # hvis 1. ord er "var":
for (i=1;i<NF;i++) $i=$(i+1) # dropp første ord (som `shift`)
if ($4 != "0)") # hvis siste arg != 0:
v = $1 # sett 'v' til variabelnavnet
} v && $0 ~ (v " = append\\(" v) { # hvis vi finner "v = append(v":
print FILENAME, NR, $0 # skriv ut filnavn, linjenr og linje
}' {} \;Det er ikke perfekt, men det er ganske bra.
P.S. To av AWK-linjene kan droppes ved bruk av $NF i
stedet for $4.
Send gjerne spørsmål eller kommentarer til Richard Tingstad :)
OLORM-9
I prosjektet nå bruker vi GitHub Actions til å bygge Docker image av Go-app.
Det er litt kjedelig å endre Go-versjon fra f.eks. 1.19 til 1.20 mange (> 1) steder.
I Dockerfile kan vi enkelt bruke
ARG/--build-arg:
ARG GO_VERSION
FROM golang:${GO_VERSION}-alpineI GitHub .workflow kjører vi også noen tester med:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-go@v3
with:
go-version: 1.20Jeg ønsker å bruke samme versjon begge steder, definert ett sted.
Helt siden Go 1.12
har go.mod inneholdt Go-versjonen.
Dette formatet er så enkelt at det ikke er vanskelig å hente ut direkte:
Each line holds a single directive, made up of a verb followed by arguments.
<go.mod tr -s ' \t\r' ' ' | sed -n '/^ *go [1-9]/s/^ *go //p'
#└┬────┘ └┬──────────────┘ └──┬──┘└─┬──────────┘└────────┬─┘
# │ │ │ │ │
# │ │ default ikke print┘ └ for linjer │
# │ │ som starter │
# │ │ med ' *go [1-9]' │
# │ │ │
# │ │ erstatt ' *go ' med '' og *p*rint ┘
# │ │
# │ └ erstatt alle [ \t\r]+ med ' '
# └ redirect go.mod til stdinMen Go hjelper oss også:
The
go mod editcommand provides a command-line interface for editing and formatting go.mod files, for use primarily by tools and scripts.
go mod edit -json | jq -r .GoSiden denne kommandoen er laget for akkurat dette formålet tenker jeg den er veldig trygg å basere seg på.
Send gjerne spørsmål eller kommentarer til Richard Tingstad :)
UPSERT
I dag hadde jeg behov for å gjøre en UPSERT i databasen min, det vil si å gjøre en INSERT, men hvis det allerede finnes i databasen gjør vi en UPDATE på det som vi har i stedet.
Jeg har en tabell som holder oversikt over hvilken organisasjon en
oppskrift tilhører, den er ganske enkel med en
organization_id og en pattern_id.
CREATE TABLE organization_patterns (
organization_id INTEGER NOT NULL,
pattern_id INTEGER UNIQUE NOT NULL,
PRIMARY KEY (organization_id, pattern_id)
);Her er pattern_id satt som UNIQUE, det vil
si at den kun kan finnes i en rad i tabellen og jeg kan derfor gjøre en
UPDATE hvis jeg prøver å gjøre en INSERT på en pattern_id
som allerede finnes. Altså at jeg bytter organisasjon til oppskriften i
stedet for å legge den til en organisasjon for første gang.
sql-spørringen min for å sette inn/oppdatere blir da:
INSERT INTO organization_patterns
(organization_id, pattern_id)
VALUES (<organization_id>, <pattern_id>)
ON CONFLICT (pattern_id)
DO UPDATE SET organization_id = <organization_id>Til slutt så tenker jeg at kanskje organization_id bare
skulle vært et eget felt i pattern tabellen og alt hadde
vært litt enklere?
OLORM-7: Gjør det vondt? Lag en subkommando.
Hei!
Jeg (i dag Teodor) synes det er viktig å ta eierskap til egen arbeidsprosess for oss som jobber med utvikling. Ofte ender jeg opp med å bygge meg et CLI for å gjøre ting lett å jobbe med. I dag vil jeg dele et konkret eksempel.
Hopp forbi Digresjon: litt Clojure-koding hvis du bare
vil lese konklusjonen.
Digresjon: litt Clojure-koding
Dette gjorde jeg i praksis i dag. Fram til nå har jeg trukket neste OLORM-forfatter sånn:
Les oppover i olorm-intern etter hvem jeg trakk forrige gang
Skriv en ny Clojure-kodesnutt for å trekke neste OLORM-forfatter. For eksempel, hvis forrige OLORM-trekking var følgende:
$ bb -e "(rand-nth '(oddmund lars richard))" oddmundSå kan neste trekking bli sånn:
$ bb -e "(rand-nth '(lars richard))" richard(når vi “går tom”, fyller vi på med Lars, Richard og Oddmund i trekke-sekken igjen)
I dag synes jeg dette var kjipt. Det var mye skriving. Så jeg bestemte meg å ta eierskap for det som gjorde vondt ved å skrive en subkommando.
Jeg startet med å skrive ned hvordan jeg ville subkommandoen skulle fungere:
$ olorm draw olr
richardDet er viktig for meg å tenke på hvilken oppførsel jeg ønsker før jeg begynner å kode. Ellers føler jeg at jeg bare surrer rundt. Og når jeg har ett eksempel på hva jeg vil at skal funke, kan jeg implementere akkurat det, uten å skrive masse kode jeg må kaste.
Jeg starter med å lage en ny subkommando som gjør at jeg kan se hva jeg driver med:
$ git diff f693631..3abc617
diff --git a/cli/src/olorm/cli.clj b/cli/src/olorm/cli.clj
index 27da7d5..3a1f0e1 100644
--- a/cli/src/olorm/cli.clj
+++ b/cli/src/olorm/cli.clj
@@ -77,12 +77,21 @@ Allowed options:
(shell {:dir repo-path} "git commit -m" (str "olorm-" (:number olorm)))
(shell {:dir repo-path} "git push"))))))
+(defn olorm-draw [{:keys [opts]}]
+ (let [pool (:pool opts)]
+ (prn `(str/blank? ~pool)
+ (str/blank? pool))
+ (prn `(rand-nth ~pool)
+ (rand-nth pool))
+ ))
+
(def subcommands
[
{:cmds ["create"] :fn olorm-create}
{:cmds ["help"] :fn olorm-help}
{:cmds ["repo-path"] :fn olorm-repo-path}
{:cmds ["set-repo-path"] :fn olorm-set-repo-path :args->opts [:repo-path]}
+ {:cmds ["draw"] :fn olorm-draw :args->opts [:pool]}
{:cmds [] :fn olorm-help}])
(defn -main [& args]Den kan jeg bruke sånn:
$ olorm draw olr
(clojure.string/blank? "olr") false
(clojure.core/rand-nth "olr") \l
$ olorm draw
(clojure.string/blank? nil) true
(clojure.core/rand-nth nil) nil(digresjon: jeg synes REPL i Clojure er fantastisk, men når jeg skriver CLI-er foretrekker jeg å jobbe direkte med CLI-et)
Så:
clojure.string/blank?kan si meg om jeg har en tom tekststreng, og gir samme svar når den får inn""ognil. (nili Clojure er somnullellerundefinedi Javascript)- Men
rand-nthbare gir megnilhvis jeg prøver å trekke fra en tom liste. (og Clojure later som atniler en “tom collection av passende type”. Dette fenomenet kalles nil-punning)
Jeg tenker å trekke personens navn fra et map sånn:
user=> (get (zipmap "olr" '(oddmund lars richard)) \r)
richardzipmap tar inn to “ting som ser ut som lister” og lager en mapping fra elementer i den venstre lista til elementer i den høyre lista.
Så jeg implementerer kommandoen sånn:
(defn olorm-draw [{:keys [opts]}]
(let [pool (:pool opts)]
(prn
(get (zipmap "olr" '(oddmund lars richard))
(rand-nth pool)))))Meeen, det er vanskelig å lære hvordan man bruker kommandoen.
$ olorm draw olr
oddmund
$ olorm draw
nilSå jeg vil ha hjelpetekst. Da skriver jeg et eksempel på hjelpeteksten jeg ønsker:
$ olorm draw
[skal returnere exit-kode 1]
???Jeg ser på en hjelpetekst som finnes:
Usage:
olorm create [OPTION...]
Allowed options:
--help Show this helptext.
--disable-git-magic Disable running any Git commands. Useful for testing.OK, nå var det lettere.
$ olorm draw
Usage:
olorm create POOL
POOL is a string that can contain the first letters of the OLORM authors.
Example usage:
$ olorm draw olr
RichardNå har jeg skrevet helptext som funker (mener jeg) i rett kontekst.
Så jeg implementerer helptext i kommandoen:
(defn olorm-draw [{:keys [opts]}]
(let [pool (:pool opts)]
(when (or (:h opts)
(:help opts)
(not pool))
(println (str/trim "
Usage:
$ olorm create POOL
POOL is a string that can contain the first letters of the OLORM authors.
Example usage:
$ olorm draw olr
Richard
"
))
(if (or (:h opts) (:help opts))
(System/exit 0)
(System/exit 1)))
(prn
(get (zipmap "olr" '(oddmund lars richard))
(rand-nth pool)))))Den kan brukes sånn:
$ olorm draw
Usage:
$ olorm create POOL
POOL is a string that can contain the first letters of the OLORM authors.
Example usage:
$ olorm draw olr
Richard… og kommandoen kan brukes neste gang:
$ olorm draw olr
larsmeeen det teller ikke, vi skal trekke på ekte i morgen.
Oppsummering
- Når noe gjør vondt i utviklingsprosessen min, prøver jeg å løse det ved å lage meg CLI-er jeg kan bruke.
- Jeg tillater meg selv å kose meg litt når jeg gjør det. Jeg mener også det er en del av jobben vår å sørge for god developer experience når vi koder.
- Hvis ingen tar ansvar for ergonomien i det vi koder, kommer det til å bli bare dritt. Så er vi i gang. The Pragmatic Programmer har et kapittel som heter “Don’t leave broken windows” om dette.
Retrospektiv
- OLORM-er skal ta 5-10 minutter å skrive. Jeg sprengte tidsskjemaet med cirka ti-gangeren. Dette setter dårlig presedens, og jeg innser at det er kjempevanskelig å vise “en liten bit uten å bruke masse tid.”
- Det var litt gøy å skrive :)
- Jeg er glad vi har et CLI for OLORM så vi kan fikse småting som “å trekke OLORM-forfatter er kjedelig”
- Hvis man skal skrive så langt som dette hver gang, er hver tredje dag alt for ofte. Jeg kunne kanskje satt av tid til en sånn en hver uke. Eller annenhver uke. Men jeg kunne jo også gjort noe “mindre”. Feks trukket en tilfeldig personlig aforisme, og forklart hva jeg legger i den.
Referanser
GeePaw Hill er en flink fyr som også snakker om hvordan vi utviklere kan ta kontroll over arbeidsprosessen vår. Hvis du synes denne artikkelen var spennnede, vil du kanskje like podcasten hans.
Semikolonfri Rust
Hvordan ville Rust-koden vår sett ut uten semikolon?
Jeg tror dette kunne vært et interessant eksperiment.
Navnet er inspirert av point-free style (PFS), uten noe mer felles enn at både SFR og PFS er paradigmer/dogmer for hvordan man skriver en del av koden sin.
Test tidlig, mens det fortsatt gjør litt vondt
Det er lett å utsette å teste det man lager på ekte brukere, det er alltid en til feature som man ønsker å ha ferdig før det er “klart”. Men man må slippe det man har laget løs mens det fortsatt føles litt tidlig og er litt ubehagelig.
I dag hadde vi en test på et design-verktøy uten blant annet innlogging, lagring og bytte av farger. Vi ville først og fremst test brukbarheten til verktøyet. Vi har en lang liste med features og fikser som vi trenger å få på plass, men tilbakemeldingene vi fikk fra brukerne våre var nesten utelukkende andre ting som vi ikke hadde tenkt så mye på. Det gjør at vi nå i mye større grad lager det viktigste først.
Vi får fokuset bort fra “en til feature” til å gjøre det man har solid og brukervennlig.
Go Single Method Interface og Adapter
(Tilsvarer Kotlin og Javas Single Abstract Method (SAM) interface / functional interface)
Grensesnitt med en enkelt funksjon er veldig praktiske:
type Greeter interface {
Greet(name string) string
}De kan enkelt sendes som parametre eller returverdier til og fra funksjoner (høyere ordens funksjoner), de kan komponeres med andre interfaces, og de er relativt enkle å implementere.
Man kan dessverre ikke (ennå hvertfall) implementere en SMI (Single Method Interface) direkte fra en funksjon, men man kan lage et Adapter. Vi lager først en funksjonstype med samme signatur som interface-funksjonen:
type GreetFunc func(string) stringog deretter implementere interfacet på denne:
func (f GreetFunc) Greet(name string) string {
return f(name)
}Nå kan vi hvor som helst enkelt implementere Greeter fra
en funksjon:
func main() {
greeter := GreetFunc(func(s string) string {
return fmt.Sprintf("Hello, %s", s)
})
greeting := greeter.Greet("Bob")
fmt.Println(greeting)
}Du har sannsynligvis brukt denne teknikken allerede vba. http.HandlerFunc.
Send gjerne spørsmål eller kommentarer til Richard Tingstad :)
En hyllest av JSON
XML og YAML har noen nyttige funksjoner som JSON ikke har, men har også mye mer kompleksitet.
JSON er så lite komplisert at spesifikasjonen kun består av fem enkle diagrammer.
Dette gjør at jeg nettopp kunne skrive et enkelt testscript helt uten noen JSON parser:
curl -s 'http://address' | tee tmp/data.json
if tr -d ' \t\n\r' < tmp/data.json |
grep '"type":"redirect"' |
grep '"action":301' |
grep '"redirectUri":"https://address"'
then
echo 'Test OK'
fiKjernen av koden er kommandoen tr -d som fjerner alle
lovlige whitespace-tegn fra JSON-dataen og slik normaliserer den. (Merk
at whitespace inni tekststrenger også fjernes, som kan være
problematisk i andre tilfeller.)
Denne koden (med unntak av curl) er en gyldig POSIX
shell-kommando og vil derfor virke på alle CI-systemer etc. i all
overskuelig fremtid.
Send gjerne spørsmål eller kommentarer til Richard Tingstad :)
OLORM-2
Nå har jeg nettopp wipet rent worktree-et mitt med
git reset --hard origin/main.
Jeg kasta arbeid fordi jeg har lært noe. Jeg ville endre på noe i et Rust-prosjekt. Jeg dro den interessante koden ut til en ny funksjon jeg kunne teste. Jeg lagde en eksempeltest som reproduserte feilen. Jeg lagde en propertytest som testet at feilen “aldri” ville oppstå.
Så begynte jeg å implementere en løsning. Men ble bitt litt av forventninger rundt hva jeg kan gjøre med dynamisk formatering av strenger.
Jeg er der i min Rust-reise at jeg stort sett klarer å få ting gjort, men jeg er ikke der at det føles riktig. Jeg vil ofte løse ting på måter som Rust enten gjør umulig (såvidt jeg vet) eller tungvint.
Jeg spurte Marcus om råd, og han foreslo å lage typer og implementere traits. Jeg tenkte at det var veldig omstendelig for å implementere den lille greia jeg holdt på med.
Men etter litt demonstrering tror jeg han har rett.
Å lage en type og implementere én trait vil ikke egentlig supplere min funksjon, men erstatte den. Semantikken i hva jeg prøver på og property testene vil også være lettere å lese og gi mer mening om jeg lager en type til dette. Og jeg tror det er lettere å finne et naturlig sted for koden å bo om dette er en egen type.
Jeg har lest at det er en vanlig misforståelse å tenke på Rust som et funksjonelt språk. Og det er nok en feil jeg gjør en del.
Jeg tror jeg vil få mer ut av å lene meg inn i typene til Rust. Med et lett dryss av objektorientering, kanskje.
En god natts søvn
I går holdt jeg på en litt kompleks refaktorering hvor jeg skal hente fargevarianter for en garnpakke fra to forskjellige steder i databasen, avhengig av om de er opprettet av designeren av oppskriften eller strikkeren har laget sin egen fargevariant. Det endte med at jeg ikke ble ferdig før jeg måtte gå hjem, og jeg så for meg at jeg trengte å bruke et par timer på det i dag. Hadde jeg blitt på jobb hadde jeg nok også lett brukt et par timer.
Når jeg kom på jobb i dag så jeg umiddelbart hva som var feil, et lite stykke unna der jeg jobbet i går, og fikset alt på ca 5 minutter.